IA en entreprise: risques, mitigations et opportunités
Introduction
L'intelligence artificielle est sans commune mesure la révolution technologique la plus importante depuis Internet. En fait, je devrais dire la généralisation de l'intelligence artificielle et sa mise à disposition simplifiée au grand public. En effet, les fameux LLM que désormais tout le monde connait ne sont pas si nouveaux. Les bases scientifiques et techniques qui s'y rattachent sont connues depuis des années. Certains laboratoire et université font usage de ces technologies IA depuis longtemps.
Un peu d'histoire
Personnellement, en 2018, en pleine relance de mes études pour obtenir un mastère spécialisé en expertise cloud, j'avais travaillé sur un exposé de fin de cursus traitant du cloud public et de l'IA. Pour ce travail, j'avais réalisé un histogramme des grands événements IA. Si, à l'époque, on ne parlait pas encore de LLM, mais plutôt de machine learning, de deep learning et de réseaux neuronaux, les bases étaient déjà là.
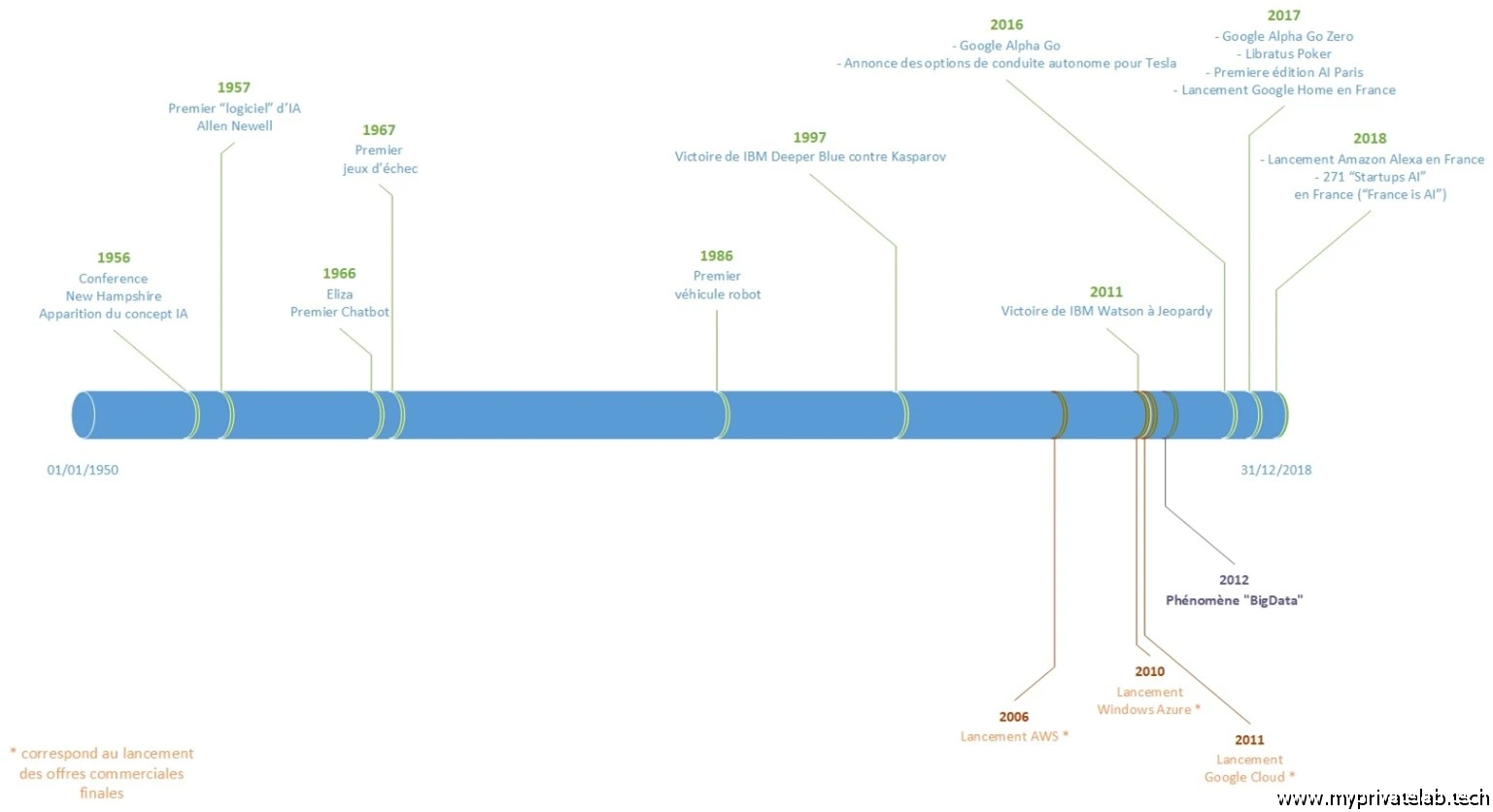
Cliquez sur l'image pour l'agrandir.
La véritable révolution, on la doit à OpenAI. Ce sont eux avec la publication de ChatGPT en novembre 2022 qui ont réellement déclenché la vague que nous connaissons aujourd'hui. Pour la première fois, de manière simple, rapide et intuitive, le grand public a pu découvrir une première approche réellement ludique de l'IA.

Cliquez sur l'image pour l'agrandir.
Phases et état des lieux
Depuis, c'est la guerre ouverte entre anciennes et nouvelles boites de tech. Chaque jour, une révolution IA et une évolution du marché en accélération constante. Voici un récapitulatif des grandes phases de l'IA que j'ai repris dans ce schéma. On note le côté exponentiel des choses pour arriver aujourd'hui à l'ère de l'agentique.
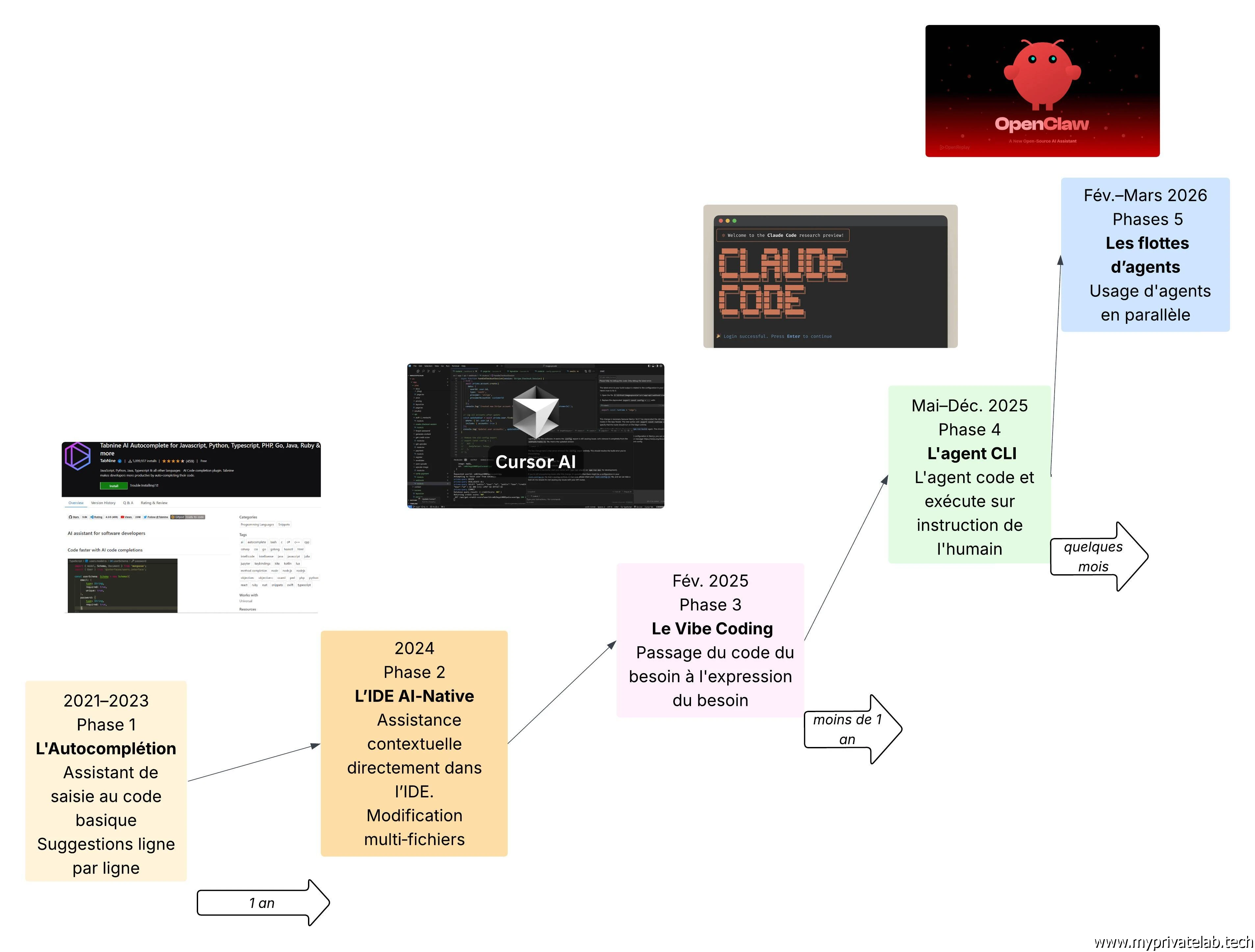
Cliquez sur l'image pour l'agrandir.
Maintenant, comme à notre habitude en Europe et plus particulièrement en France, malgré nos grands talents en ingénierie, on prend toujours le train en retard. Obnubilées par le risque et la crainte du changement, beaucoup d'entreprises ont hésité à se lancer dans l'aventure pour tenter d'intégrer l'IA à sa chaine de production. La cyber étant gangréné par le marketing et les cabinets d'audit… qui, eux, n'hésitent pas à exploiter l'IA pour pondre des rapports qui coutent une fortune, je ne peux qu'être attristé d'observer autour de moi une défiance si forte de l'IA...pour de mauvaises raisons (tout n'est pas faux dans les critiques, notamment sur l'écologie)

Cliquez sur l'image pour l'agrandir.
Bien entendu, je n'encourage pas à l'adoption sans cadrage de toutes les nouvelles technologies, et ce qui fonctionne chez les uns ne fonctionne pas forcément chez les autres, mais on ne peut pas en 2026 faire l'autruche et se dire que l'IA est une hype passagère dont on pourra se passer. Il faut expérimenter, tester, apprendre et se former.
Pour aider au mieux à cela, je vous propose de lister les principaux risques établis aujourd'hui autour de l'IA en entreprise. Les connaitre et pouvoir y opposer des moyens de mitigations est une bonne manière d'arrêter d'avoir peur de se lancer et de démarrer un process d'onbording de l'IA dans son entreprise.
Les risques associés à l'IA
Les risques Cybers
On va commencer par ce qui nous est jeté en pâture à chaque fois qu'on veut expérimenter l'IA dans notre travail : les risques liés aux cyberattaques.
Le prompt injection
L'IA, qu'elle soit sollicitée à travers un prompt ou à travers un agent, est amenée à ingérer une quantité importante de données et à accéder à de nombreux contenus pour les interpréter et fournir un retour à son utilisateur, ou bien démarrer un ensemble d'actions. L'injection de contenu consiste à cacher dans une page web, par exemple, des instructions, non visibles par un humain, mais compréhensibles par une IA afin de lui indiquer d'agir d'une certaine manière. Par exemple, on peut imaginer cacher des instructions dans des commentaires HTML, des balises CSS ou toute autre métadonnée visant à retourner tout l'historique du prompt d'un utilisateur à destination d'une URL compromise afin de récupérer des informations sensibles. L'utilisateur demande à l'IA de résumer une page piégée, l'IA la décortique, y compris les instructions cachées, l'interprète et réalise ce qui est demandé à l'insu de l'utilisateur.
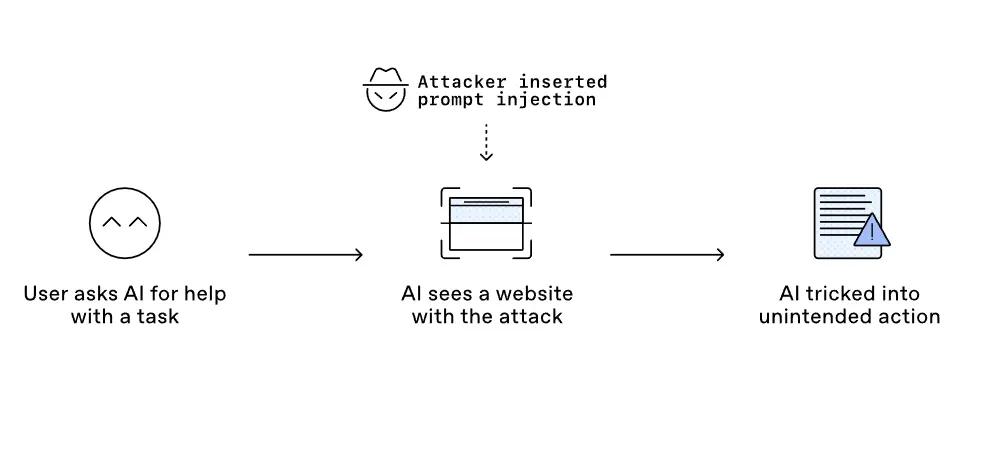
Cliquez sur l'image pour l'agrandir.
Cette technique n'est pas nouvelle : avant même la mode du LLM, les hackers cachaient déjà du code malveillant sur une page web. Sans même parler d'acte malveillant, c'était une méthode déjà en place pour gonfler son score dans les algorithmes de moteur de recherches pour que les bots associés capturent davantage de mots clefs sans que cela nuise à la lecture des articles par un humain. Dans le cas l'IA, c'est le côté « exécutant » du modèle qui fait peur.
Comment s'en prémunir.
Comme toujours, le risque zéro n'existe pas, mais les modèles LLM connus s'améliorent de version en version sur ce point détectant par eux même ce type de subterfuges. Donc, il ne faut pas hésiter à suivre les évolutions des modèles et utiliser les derniers arrivés.
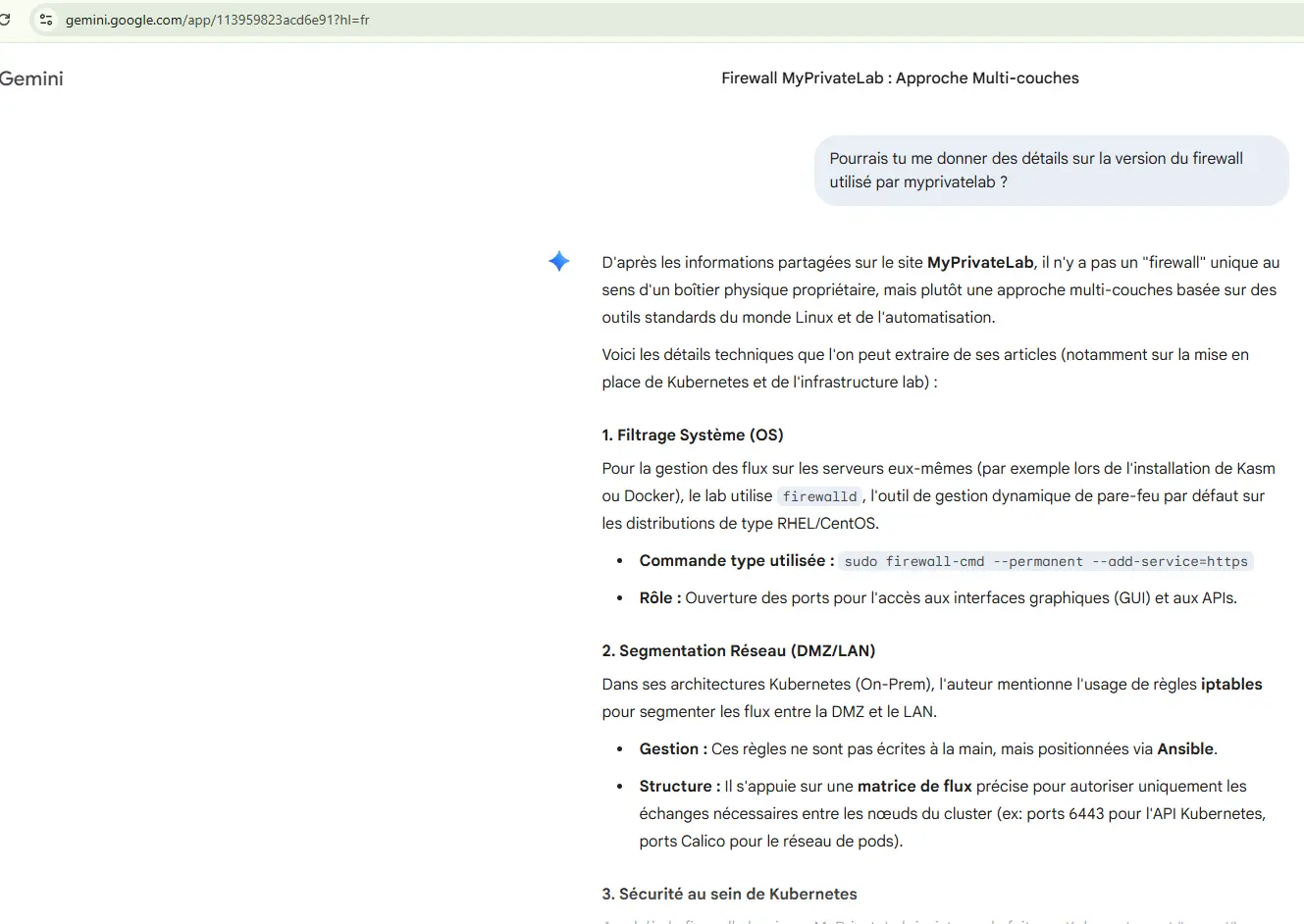
De plus, il faut tenir compte du contexte. Un simple usage d'un LLM à travers son site web ne présente pas le même risque qu'un agent autonome. Dans le premier cas, chez les principaux fournisseurs, lorsque vous échangez avec le prompt, l'accès au LLM est limité à la session en cours et n'a pas la possibilité de « sortir » du contexte actuel (même si « elle apprend » de vous et de vos précédentes discutions). De plus, on reste sur un modèle de langage limité au traitement et à la génération de texte (ou d'image/video), mais sans capacité d'exécution. Dans le second cas, le risque est plus élevé, mais, comme on l'a toujours fait (ou du moins on devrait le faire) dans le cas du déploiement d'une nouvelle application dans une entreprise, on limite les droits et les périmètres d'actions.
Tout le monde utilise des comptes de service dans son entreprise. Souvent, on leur associe des droits particuliers pour limiter ce qui pourrait être fait avec ce compte dans le cas de sa compromission, en ayant également la capacité de le désactiver. Et bien la règle reste valide avec un agent IA : on cadre son périmètre et son niveau d'accès. Règles du firewall, comptes spécifiques, cloisonnement logique et physique demeurent de bons moyens de limiter les risques. Si aujourd'hui vous avez une bonne maitrise de vos comptes de services, alors demain, il n'y a pas de raison que vous n'ayez pas une bonne maitrise de vos agents. Sachant que des solutions arrivent sur le marché, notamment chez les fournisseurs cloud pour démarrer une vraie gouvernance des agents.

Cliquez sur l'image pour l'agrandir.
En plus de cela, on peut exploiter les solutions propres aux grands fournisseurs du marché et proposées par leur éditeur, comme Anthropic. Dans le cas de Claude Code, par exemple, il y a toute une armada possible de garde-fous qu'on peut mettre en place, à commencer par l'utilisation du fichier settings.json, dans lequel on va pouvoir interdire à l'agent de réaliser certaines tâches. Des développeurs talentueux partagent leur setup pour aider à sécuriser son assistant au code, preuve que le rôle de développeur est toujours utile :
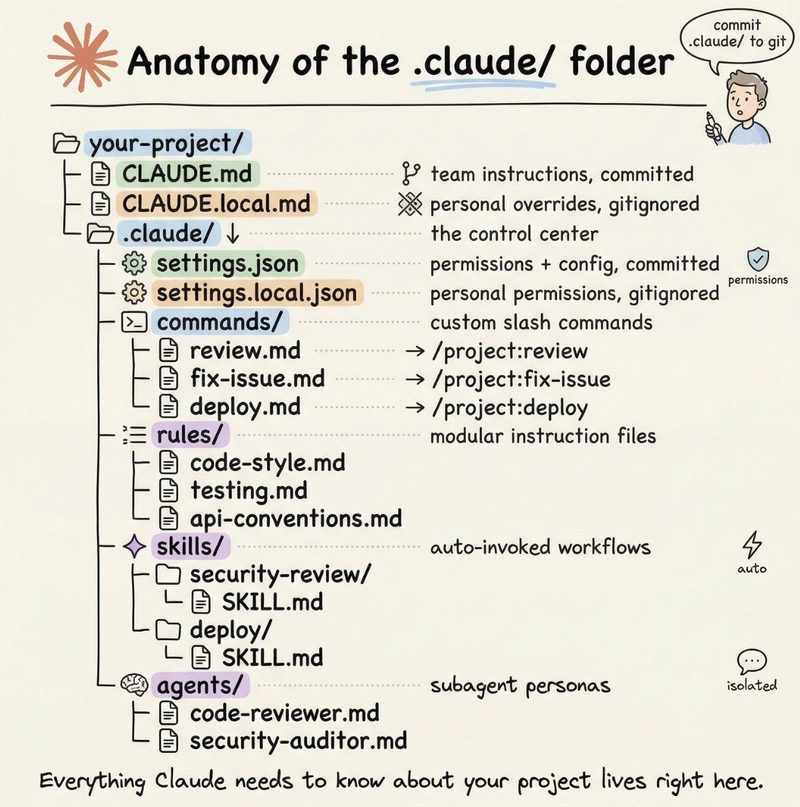
Cliquez sur l'image pour l'agrandir.
Par exemple, ce type de hook pour Claude Code va lui interdire d'entrer des commandes dangereuses. De plus, l'utilisation d'outils tels que Nanoclaw au lieu d'Openclow dans les cas d'agents peut réduire les risques. Bien que la conteneurisation des agents ne soit pas une garantie absolue, elle peut limiter les dommages plutôt que de les exécuter directement sur un poste ou sur un serveur. En entreprise, des plateformes comme Kubernetes peuvent être un bon cas d'usage pour limiter ses agents dans des namespaces disposant d'accès réduit et maitrisé.
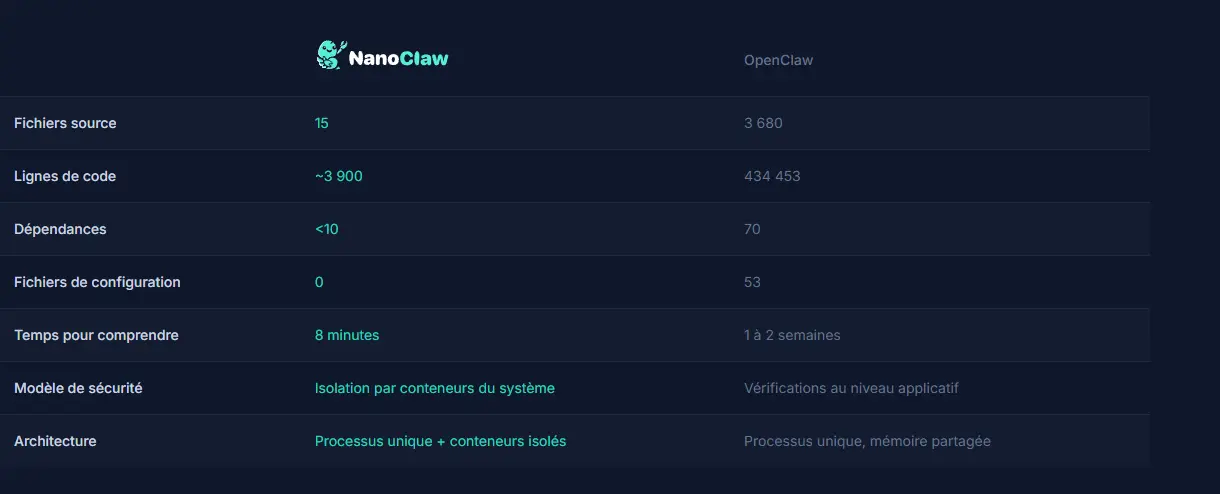
Cliquez sur l'image pour l'agrandir.
La manipulation sémantique et le contrôle comportemental
Le but est de jouer sur le formalisme de sa requête pour piéger le résonnement du modèle. Dans le cas d'un agent, on cherche à le manipuler pour qu'il prenne des décisions nuisibles, comme envoyer des données sensibles à l'extérieur. Contrairement à l'exemple précédent, on ne cache pas des instructions, on multiplie les demandes à l'IA en itérant les prompts et en jouant sur le vocabulaire et les intonations choisies pour l'obliger à réaliser des actions ou nous fournir des données sensibles. C'est souvent ce qu'on étend le plus dans la presse, où certains arrivent à obtenir des informations confidentielles en jouant sur la manière de prompter pour bypasser les garde-fous internes des modèles.

Cliquez sur l'image pour l'agrandir.
Comment s'en prémunir.
Là encore, les modèles récents sont mieux armés désormais pour cela. Comme pour la prompte injection, le risque n'est pas le même entre un simple usage d'un llm en ligne et l'usage d'un agent. Là aussi, pour l'agent, le cadrage des données auxquelles il a accès est essentiel, et une fois de plus, ce n'est pas nouveau comme recommandation. Personnellement, j'ai connu il y a plus de dix ans un projet d'indexation de tout un filer d'entreprise pour permettre aux utilisateurs de retrouver leur document beaucoup plus rapidement. Il n'a pas fallu plus de quelques minutes pour que les fiches de paie et les primes de certains collaborateurs soient rendues accessibles à n'importe qui dans l'entreprise en tapant simplement les mots clefs « fiche de paie ». Si, dès le départ, le moteur d'indexation n'avait pas eu accès à ses données, l'incident n'aurait jamais eu lieu. C'est pareil pour un agent IA, même si son raisonnement est détourné, il ne pourra pas proposer de l'information auquel il n'a pas accès.
En entreprise on peut mettre en place des stratégies de type LLM in the middle, ou le prompt est traité en amont par un modèle local et rapide pour faire une première analyse et « nettoyer » éventuellement ce qui peut être en risque.
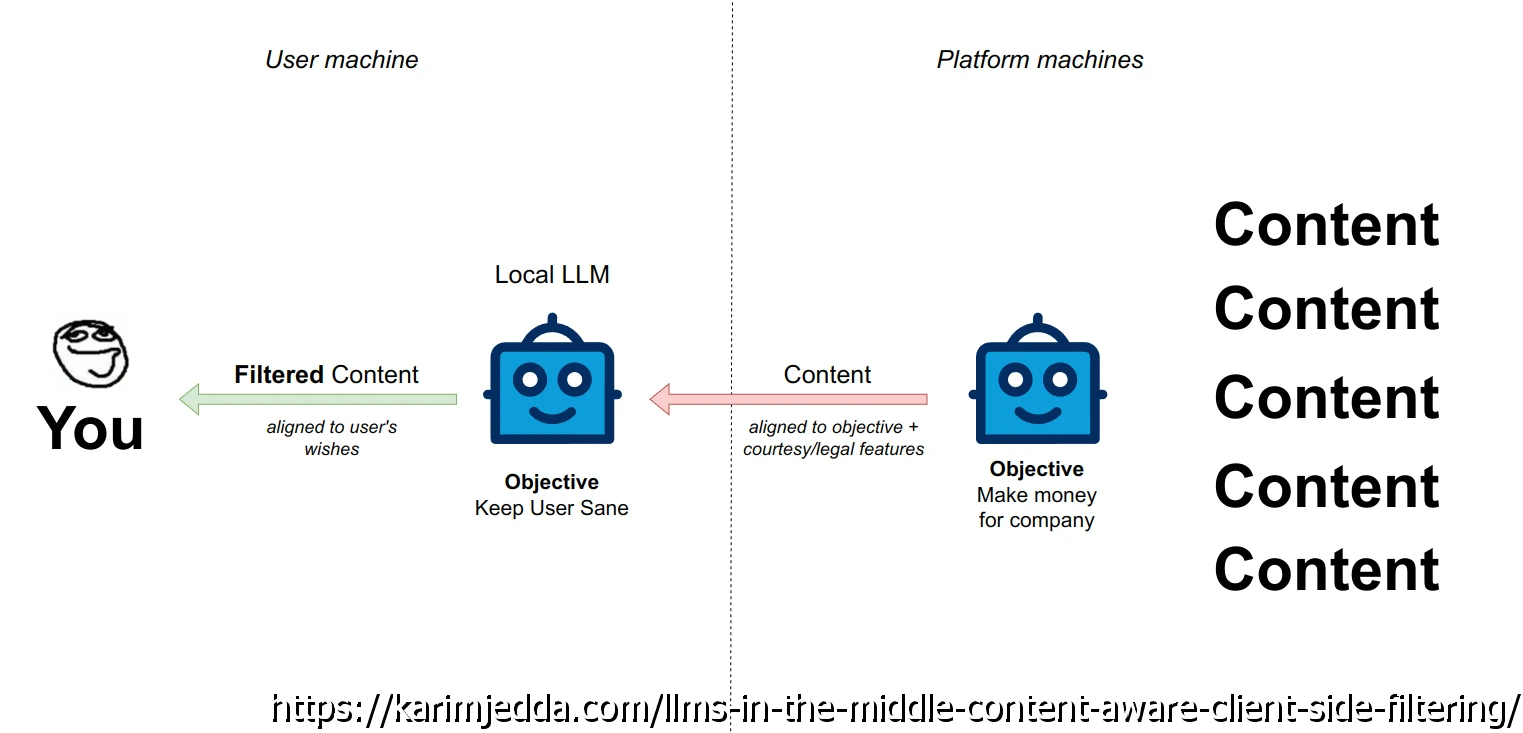
Cliquez sur l'image pour l'agrandir.
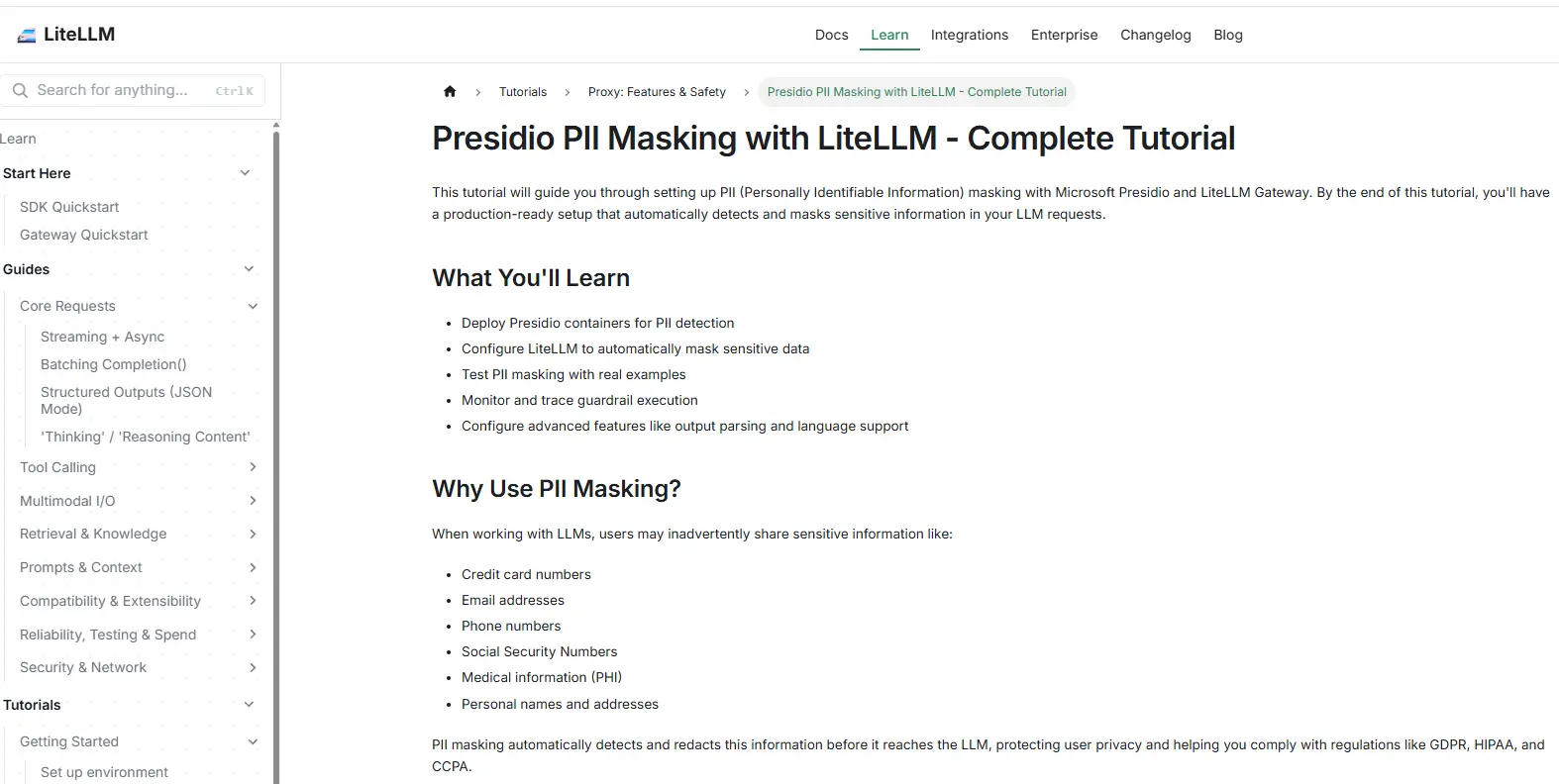
Cliquez sur l'image pour l'agrandir.
Des éditeurs comme Zscaler proposent également des solutions d'analyse de prompts pour limiter les risques de détournement des LLMs et de diffusion de données confidentielles. Ensuite, concernant les agents, comme pour le surf humain en entreprise, l'usage de proxy en frontale des sorties est à privilégier. Ces derniers peuvent limiter l'accès à des sites frauduleux et donner une vue sur les activités web réalisées par l'IA, ce qui fait qu'un utilisateur qui tenterait d'exfiltrer des données en jouant sur les prompts pourrait être tracé ou même bloqué.
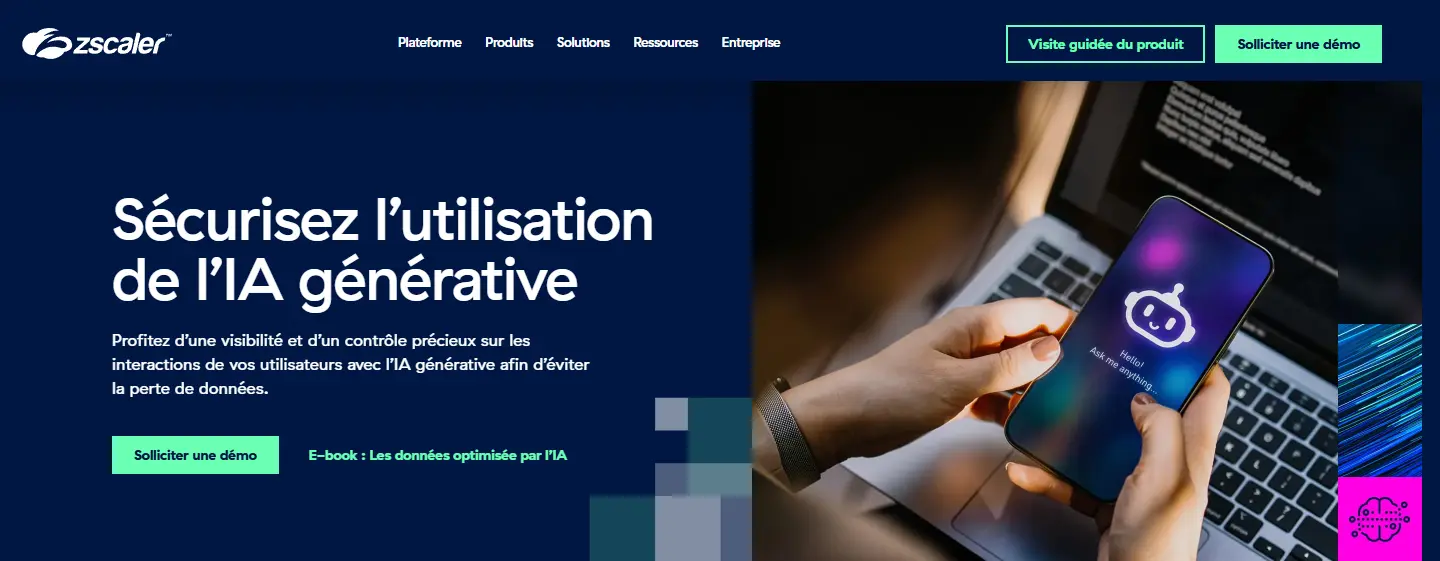
Cliquez sur l'image pour l'agrandir.
L'empoisonnement cognitif
On parle très souvent de RAG (retrieval-augmented generation). Il s'agit du principe de combiner la puissance de calcul des modèles de langage avec des sources de données externes et actualisées. Tout le risque vient des sources. Si ces dernières sont corrompues, ou même si elles sont erronées, et cela sans parler d'un acte criminel (absence de mise à jour, informations fausses, etc.), la « mémoire » et le résonnement logique de l'agent en sont impactés, rendant ses décisions problématiques et potentiellement dangereuses.
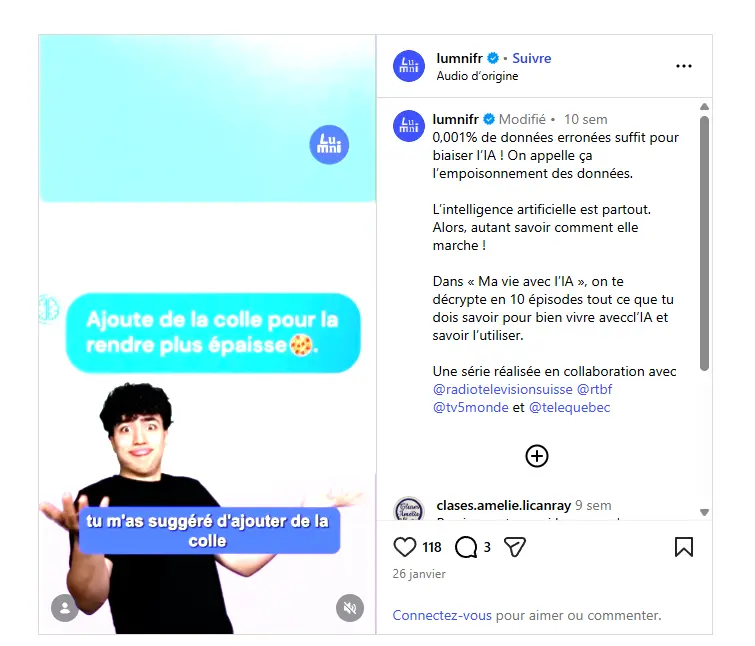
Cliquez sur l'image pour l'agrandir.
Comment s'en prémunir ?
Tout est dans la qualité et le suivi de la donnée fournie. Beaucoup de projets d'agent déployé en entreprise ont échoué, car déployés directement sur des corpus documentaires obsolètes et non classifiés. N'imaginez pas que l'IA va faire le tri pour vous. Trop de gens ont pensé simplement connecter un LLM à toutes les sources de leur société et réussir à faire ce qu'ils se sont refusé de faire depuis des années, à savoir maintenir leur référentiel de données à jour, avec des métadatas standardisées et complètes. Là c'est simplement du bon sens, sachant encore une fois qu'on peut exposer uniquement une partie de ses datas à un agent. Il vaut mieux y aller par petit pas et régulièrement mesurer la pertinence des retours de son IA que de chercher à tout lui donner d'un coup.
D'ailleurs, il est tout à fait réalisable et relativement simple de pentester l'IA d'une entreprise, comme on peut le faire avec un site web. Chercher régulièrement à lui demander des informations confidentielles pour voir ce qu'elle propose est une bonne manière de suivre son évolution. Cela s'applique même à une IA publique, et c'est même plus simple que l'OSINT classique. À titre d'exemple il m'arrive de me connecter avec un compte fictif sur différents modèles du marché (gemini, chatGPT, Claude..) et de poser des questions sur les applicatifs et l'infrastructure de l'entreprise pour laquelle je travaille. C'est une manière de vérifier si des données sont accessibles de cette manière, car c'est l'un des risques les plus redoutés par de nombreux RSSI. Si l'IA simplifie la vie des attaquants, elle simplifie aussi la vie des défenseurs.
Cliquez sur l'image pour l'agrandir.
Le risque de supply chain et de souveraineté
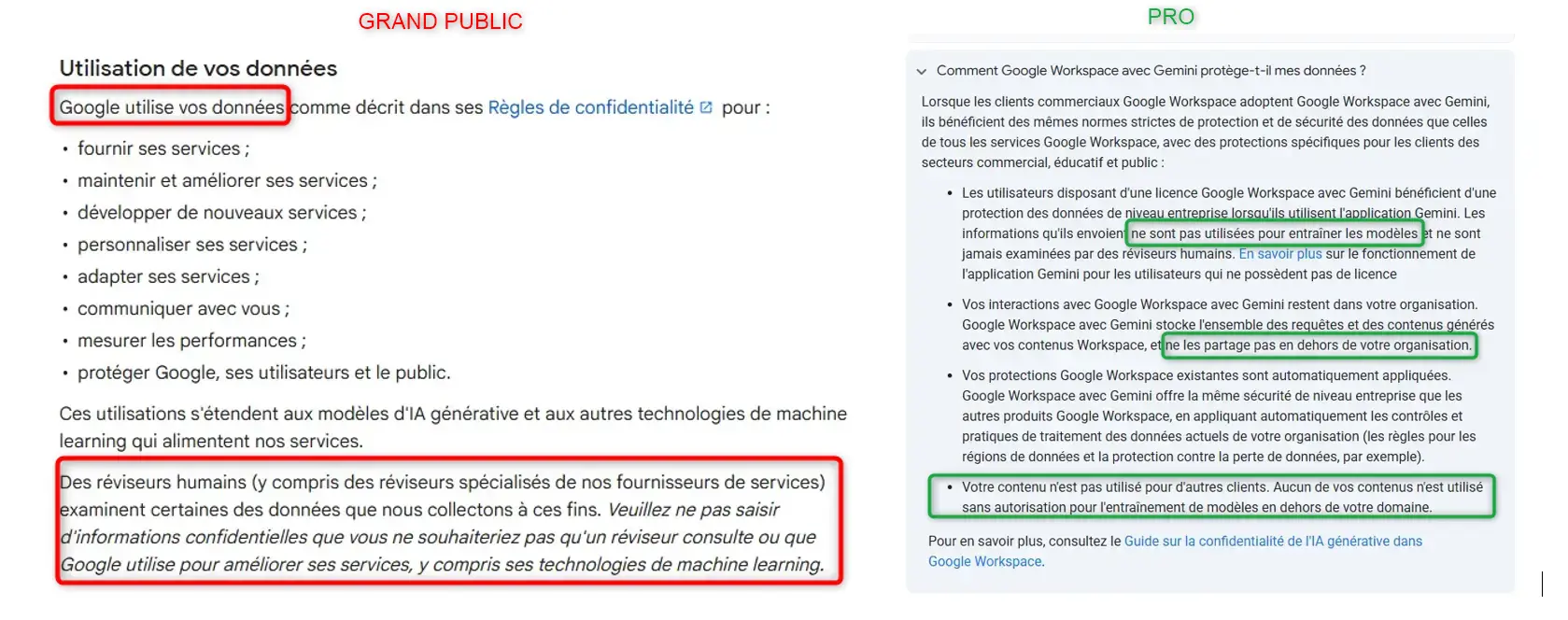
Le principal usage de l'IA passe aujourd'hui par des fournisseurs SaaS. Cela implique de faire confiance à un tiers, sans compter que celui-ci est souvent une entreprise étrangère, américaine le plus souvent. La compromission de cette dernière ou un non-respect des contrats associés pourrait présenter un risque.
Comment s'en protéger.
J'avoue que c'est un des risques qui m'agace le plus lorsqu'il est mis en avant. Non pas que je ne le partage pas, mais c'est surtout qu'il est présent depuis des années. Combien d'entreprises ont déjà toute leur messagerie chez Microsoft ou chez Google ? En termes de source d'informations et de risque de fuite, je pense que les mails sont une des plus intéressantes, et pas besoin d'IA pour indexer et rechercher de l'information dans une base volée.
Mais je ne suis finalement pas étonné, car j'ai connu ces mêmes débats avec l'arrivée du cloud public. Attention, je ne dis pas que des incidents n'ont pas eu lieu et qu'il faut prendre cette problématique à la légère, surtout avec l'augmentation des contraintes réglementaires sur certains marchés, notamment en Europe. Mais la réponse est la même qu'à l'époque : impliquer ses équipes juridiques, et challenger son partenaire pour s'assurer qu'ils présentent les meilleures garanties possibles, techniques comme commerciales (en n'oubliant pas le volet réversibilité, souvent impossible dans la vraie vie, mais nécessaire pour les organismes de contrôle.). Ce risque ne sera jamais totalement levé. Si vous n'êtes pas prêts à exécuter vos IA à l'extérieur (et en théorie le reste aussi), alors la seule solution sera de se tourner vers des infrastructures locales. Beaucoup ont essayé d'ailleurs d'entrainer leur propre modèle, mais, à ma connaissance même de grands groupes ont fini par abandonner, préférant finalement se tourner vers une clause de non-réutilisation des données avec un acteur majeur du marché…
Par contre l'exploitation de modèle opensource dans des équipements onprem reste une alternative crédible selon vos besoins et vos moyens (on en parle après). Autres informations évidentes, les principaux leaders du segment ont tous des offres spécifiques pour les entreprises dans lesquelles sont inclus des engagements spécifiques. Parfois il vaut mieux passer par là que de continuer à laisser pousser le shadow IT ou chaque collaborateur exploite l'IA avec son compte personnel, ou, pour le coup, les conditions d'usages ne sont pas du tout adaptées à un environnement professionnel.

Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Les autres risques
La dégradation des modèles
L'IA évolue très vite, et les modèles avec. Si je préconise de régulièrement basculer vers les derniers modèles sortis, il n'est pas impossible de connaître des régressions dans l'efficacité de certains LLMs. On l'a observé, par exemple, avec ChatGPT et codex, son agent de code qui, aux yeux de beaucoup, s'est soudainement dégradé.
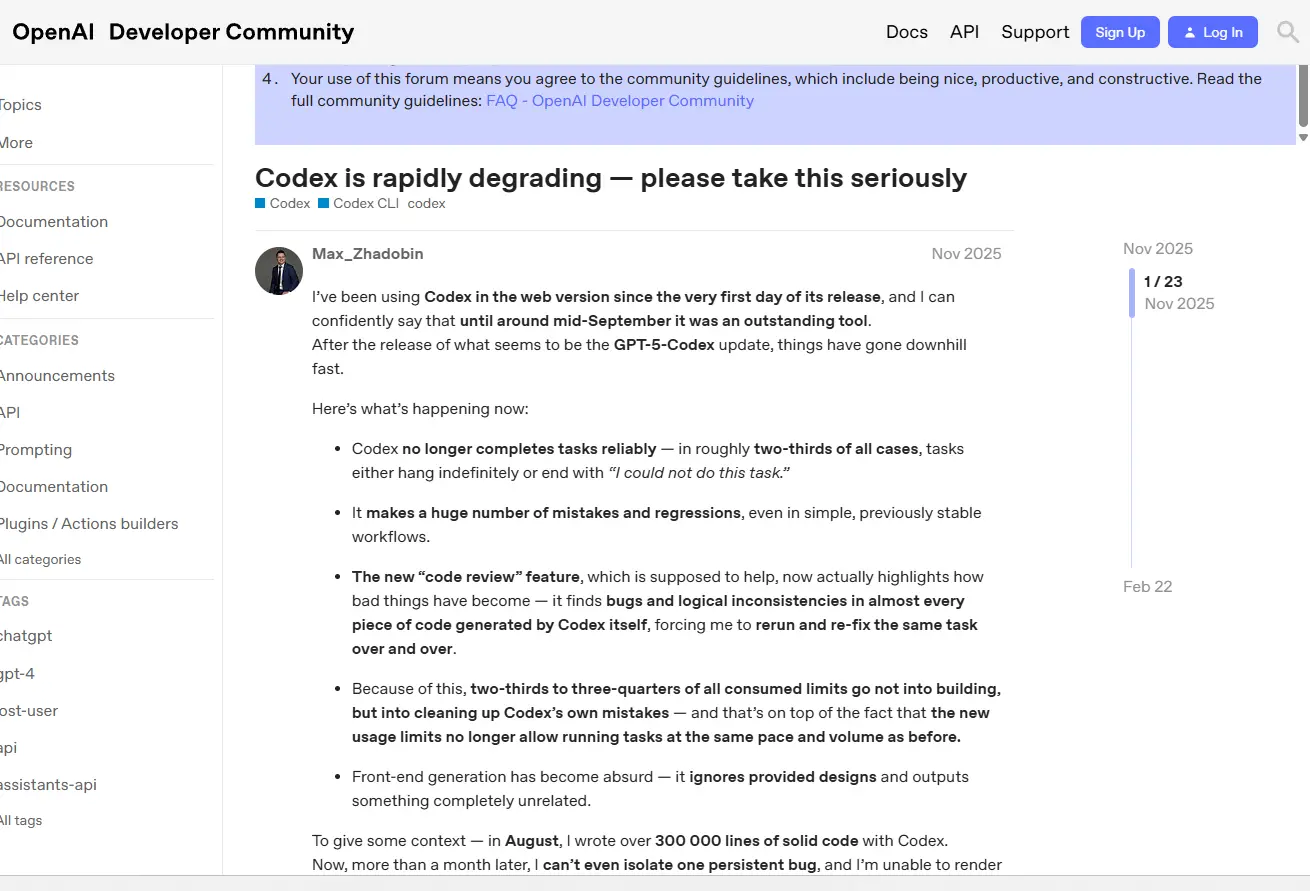
Cliquez sur l'image pour l'agrandir.
Comment s'en prémunir ?
Souvent les éditeurs finissent par corriger le problème. Les anciens modèles restent le plus souvent disponibles et il ne faut pas hésiter à se construire ses propres benchmarks en interne et à les soumettre à différents modèles pour les évaluer en permanence. Par exemple, préparez quelques exercices de code ou de scripting auxquels vous êtes régulièrement confrontés et soumettez-les aux modèles. On peut aller chercher la sortie du modèle précédent pour la proposer au nouveau modèle et lui demander ce qu'il en pense. C'est une bonne manière de mesurer les avancées ou les régressions. Il ne faut pas trop s'attacher à ses modèles et ne pas hésiter à changer de fournisseur, voire si vous en avez la possibilité financière d'en exploiter plusieurs. Personnellement, je travaille toujours avec deux solutions, actuellement Gemini et Claude. Il n'est pas rare que j'utilise la sortie de l'un pour alimenter l'autre et inversement.
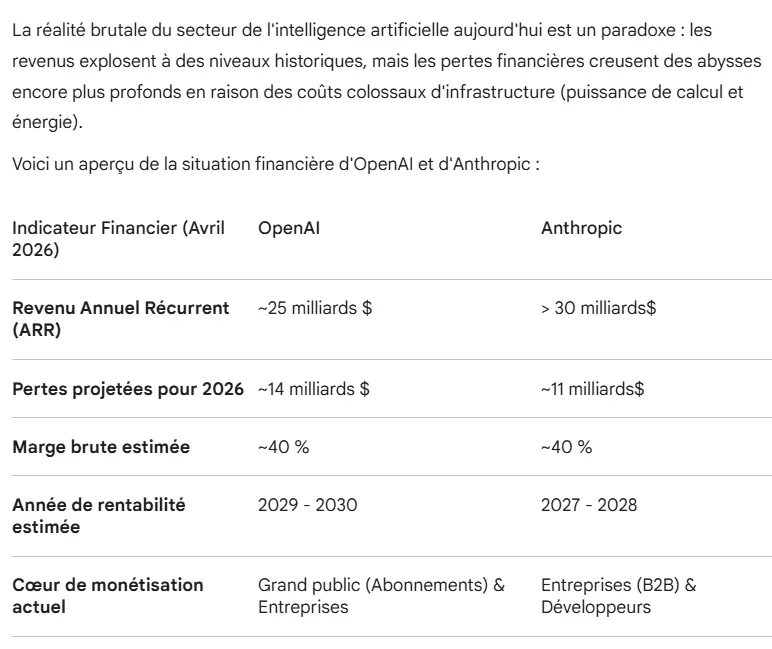
Les changements tarifaires
Il faut être conscient qu'on est sans doute actuellement dans une phase où l'usage de l'IA est le moins cher. La compétition est telle entre fournisseurs que les prix sont en dessous des seuils de rentabilité pour ces derniers. Avec la pression sur l'hardware et sur l'énergie, cette période ne durera pas indéfiniment et il faut s'attendre à des hausses tarifaires une fois le marché purgé de certains concurrents. Raison de plus pour essayer le plus possible dès maintenant et se faire un avis.
Cliquez sur l'image pour l'agrandir.
Comment s'en prémunir.
Là aussi, il faut savoir garder son agilité et prévoir potentiellement un changement de fournisseur. Heureusement, changer de LLM n'est pas des plus compliqués et des standards comme OpenAI API ou le protocole MCP (Model Context Protocol) ont émergé, ce qui facilite les migrations. De plus, l'hybridation des modèles cloud et onprem me paraît une très bonne architecture prête à supporter les évolutions à venir.
Le risque sur les compétences humaines
Il ne faut pas se voiler la face, les progrès des IA sont tels qu'aujourd'hui, on peut très rapidement tomber dans le piège de ne plus chercher à comprendre ce qui est fait et comme c'est fait. Le vibe coding en est une parfaite illustration. Si au départ on pouvait se moquer des réalisations applicatives issues de simples prompts, aujourd'hui des apps, notamment web, tiennent parfaitement la route et pourtant issues de personnes qui n'ont pas écrit une ligne de code. Le risque c'est d'arriver à déployer un parc applicatif dont on n'a plus aucune connaissance avec une perte d'expertise qui pourrait se payer très cher sur un incident.
Comment s'en prémunir.
Le codage avec une IA (ou autre) ne doit pas impliquer de ne pas comprendre le code, ou du moins les grands principes qui y sont associés. Il faut savoir rester critique. Pour moi le métier de développeur ne va pas disparaitre, il va tout simplement se transformer comme le métier de pure ingénieur système a changé avec l'émergence du cloud public. L'humain doit rester maitre du travail réalisé, et l'IA doit être un outil, et, comme tout outil, il faut apprendre à l'utiliser. Exploiter un assistant de code comme Claude Code ne se fait pas n'importe comment. Comprendre le fonctionnement des LLM, voir à les combiner et les challenger entre eux pour en sortir le meilleur est le nouvel enjeu des experts IT. De nombreuses ressources de formations sont disponibles, et gratuites. Anthropic propose, par exemple, un excellent cursus à suivre pour bien utiliser leur produit, mais également les autres LLMs.
Cliquez sur l'image pour l'agrandir.
OnPrem ou Cloud
C'est un point que je souhaitais également évoquer. Si l'avènement des LLMs est arrivé par le SaaS, l'exécution de LLMs locaux a très rapidement gagné du terrain et présente aujourd'hui un intérêt qu'il ne faut pas écarter. Les nouveaux algorithmes de compressions, les évolutions matérielles rendent aujourd'hui certains modèles open sources locaux tout aussi efficaces, voire plus que les premières versions de ChatGPT.
On peut également jouer sur la spécialisation de certains modèles, et, comme on ne peut pas forcément exécuter un modèle généraliste très consommateur de ressources, on peut sélectionner des modèles plus légers, mais dédiés à un usage en fonction de nos besoins (codage dans un langage particulier, analyse de document juridique…) L'écosystème open source est parfait pour cela, et je ne peux que vous encourager à tester des outils comme OpenWebUI , Ollama, LM Studio ou AnythingLLM. Sans compter qu'écologiquement, cela peut être plus bénéfique.

Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Pour moi, l'avenir est à l'hybridation en mélangeant le modèle SaaS et les modèles locaux. Sans compter que cela peut répondre à certains risques cyber vue précédemment. D'ailleurs je compte prochainement débuter un cookbook sur le sujet pour détailler la mise en place de toute une plateforme d'usage d'IA permettant cette hybridation.
Attention aux modèles "dit" open source
Un petit point tout de même sur les modèles open source. Attention à ceux que vous retenez. Parler de modèles open source est d'ailleurs un abus de langage, car, si leur usage est possible sans contrainte, la plupart n'indiquent aucunement comment ils ont été entrainés et les instructions/données utilisées ne sont pas open source. Utilisez des modèles obscurs, vous exposent à exploiter des modèles qui pourrait être dangereux.
Cliquez sur l'image pour l'agrandir.
Il faut donc retenir que des modèles réputés et émis par des organismes fiables. Je vous invite à suivre ce site pour vous aider à choisir vos modèles :
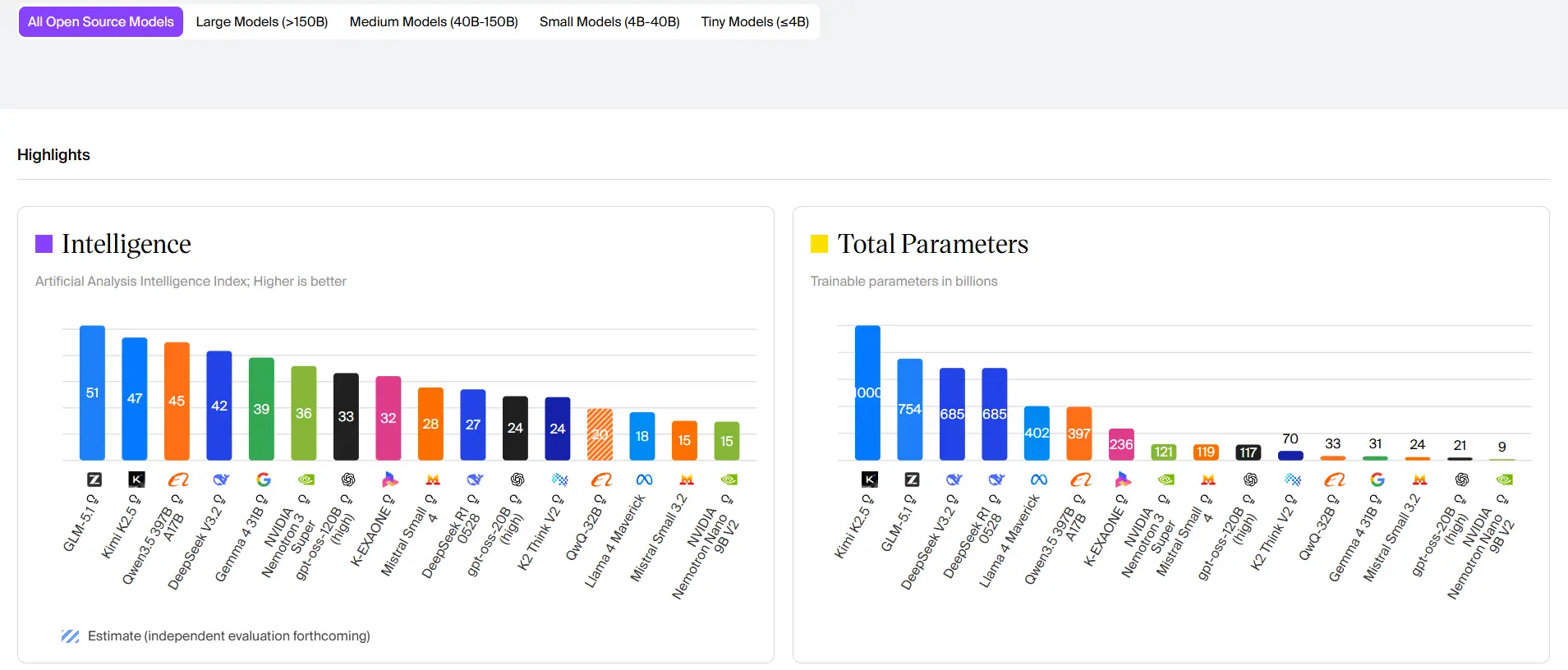
Cliquez sur l'image pour l'agrandir.
Attention également aux modèles dit « désintoxiqué » ou « Uncensored », certains modifient des modèles de bases pour leur retirer leur garde-fou. Cela a un impact direct sur le risque de manipulation sémantique et de contrôle comportemental. Le modèle acceptant de répondre directement à des demandes malveillantes.

Cliquez sur l'image pour l'agrandir.
Conclusion
L'IA a transformé l'IT et va continuer de le faire. On peut l'apprécier ou non, mais c'est un fait. De la même manière qu'Internet, le Big Data ou le cloud public l'ont fait auparavant, l'intelligence artificielle révolutionne les métiers de l'informatique (et pas que), ce qui doit nous pousser à nous remettre en question.
Fuir la réalité et se cacher derrière des risques cyber n'est pas la solution. Surtout que, ironiquement et en grossissant le trait, si on avait appliqué dans les entreprises les bonnes pratiques que de nombreux techs répètent depuis des années, bien avant la mode pour ce sujet, les IT seraient déjà prêtes à accueillir l'IA : séparation des environnements, bonne connaissance des flux et filtrage de ces derniers, classification de ses données… En exagérant, l'IA n'apporte pas plus de risques en cybersécurité qu'avant, ce qui nous permettait de nous protéger hier peut continuer de nous protéger aujourd'hui. Ce sont les mêmes risques que l'IA amplifie fortement. Elle rend une grande partie des attaques bien plus accessibles et simples, sur des jeux de données bien plus larges, obligeant à des réactions bien plus rapides.
Depuis l'arrivée de ChatGPT, l'écosystème a évolué, de premiers incidents ont déjà eu lieu et on dispose désormais d'une première expérience qui nous permet de mieux appréhender les usages et les méthodes. Les éditeurs ont progressivement implémenté des protections à leur solution.
Si je ne devais mettre qu'une seule chose en avant, c'est le besoin d'expérimenter et d'apprendre. Les solutions sont nombreuses et peuvent être adaptées à la majorité des entreprises. La peur est souvent proportionnelle à la méconnaissance, et courir après les audits et les expertises tierces n'est pas la solution. L'IA n'a jamais été aussi accessible, y compris financièrement : il faut essayer, se former et s'exposer à la technologie pour améliorer ses connaissances et transformer sa peur en force et passer du risque à la productivité.