XCP-ng: Evolution du Lab V2.0 - Déploiement du stockage partagé XOSTOR et usage de Live Migration
Introduction
Après s'être occupé du réseau, il est temps de s'occuper du storage.
Pour bénéficier de véritables fonctionnalités de haute disponibilité (HA), il est essentiel de posséder un espace de stockage partagé pour les machines virtuelles (VM) utilisable par l'ensemble des trois serveurs constituant le pool.
Plusieurs solutions s'offrent à nous. Le plus simple est l'usage de NFS (Network File System). On pourrait imaginer un volume déployé sur un NAS comme sur mon Terramaster F4, le monter sur chaque node et créer un SR (Storage Repository) au niveau du pool.
Si cette méthode est parfaitement supportée, elle suppose dans mon cas des performances NFS suffisantes. Or, bien que performant, mon NAS ne dispose pas d'interface 10G et demeure sollicité pour d'autres usages.
NFS est déjà utilisé au sein du homelab pour fournir les ISOs aux VMs, mais mon NAS n'a pas les capacités suffisantes pour l'exécution de VMs.
XOSTOR
L'autre alternative, propre à XCP-ng est d'utiliser XOSTOR.

Cliquez sur l'image pour l'agrandir.
Comme décrite sur le site de Vates, XOSTOR est une solution d'hyperconvergence pour XCP-ng qui s'appuie sur la technologie DRDB pour agréger les disques locaux en un SAN (Storage Arena Network) virtuel performant.
Pour ceux qui chercheraient à faire des parallèles avec VMware, c'est un peu le VSAN de XCP.
Par contre, contrairement à son concurrent, XORSTOR s'appuie entièrement sur des briques OpenSource.
DRBD
En effet, la description du produit parle d'une base DRDB.

Cliquez sur l'image pour l'agrandir.
DRBD pour (Distributed Replicated Block Device) est une solution logicielle open-source pour Linux qui permet de répliquer des données entre des serveurs en temps réel.
Pour faire simple, on pourrait parler de RAID 1 via le réseau. Au lieu de transférer des données entre deux disques dans la même machine, DRBD transfère des données d'un bloc de disque d'un serveur vers un autre serveur à travers un réseau (pour nous, le réseau 10G sur lequel on a créé un VLAN).
DRBD se situe dans la pile logicielle juste au-dessus du disque physique (ou du volume logique LVM) et en dessous du système de fichiers.
Son fonctionnement s'articule en 4 phases :
- L'écriture : Lorsqu'une application écrit des données sur le disque du serveur A (Primaire).
- L'interception : DRBD intercepte cette écriture.
- La réplication : DRBD envoie simultanément les données vers le serveur B (Secondaire) via le réseau (à noter que la réplication peut se faire vers plus qu'un seul serveur secondaire pour avoir davantage de résilience, au détriment d'un espace consommé plus important).
- La validation : Une fois que le serveur B a confirmé l'écriture, le serveur A valide l'opération à l'application.
DRBD est une solution qui existe depuis 2001 et toujours activement soutenue et développée par l'entreprise autrichienne LINBIT.
LINSTOR
D'ailleurs la société propose également un autre outil, également utilisé par XOSTOR: LINSTOR.

Cliquez sur l'image pour l'agrandir.
DRDB est le moteur de réplication, LINSTOR est le gestionnaire de réplication. L'un fait le travail, l'autre coordonne et gère la configuration.
En effet DRDB est quelque peu complexe à mettre en œuvre, LINSTOR vient ajouter une couche d'abstraction venant simplifier la gestion et le déploiement de DRBD, notamment quand il s'agit de le déployer sur un grand nombre de serveurs.
On retrouve deux composants :
- LINSTOR Controller : c'est le cerveau. Il possède la base de données de tout le cluster. C'est à lui que vous envoyez vos commandes de configuration et de gestion.
- LINSTOR Satellite : C'est un agent installé sur chaque serveur de stockage. Il attend les ordres du Controller pour créer un volume LVM, activer une réplication DRBD ou supprimer une ressource.
À noter que LINSTOR peut s'exploiter sous Kubernetes via un driver CSI et également être exploité avec ProxMox ou OpenStack, même si, sur ces plateformes, on rencontre plus souvent CEPH.
Mais là où, justement, CEPH couvre plusieurs types de stockage, le combo LINSTOR/DRDB ne traite que le mode bloc (comme Longhorn), ce qui en fait une solution très performante.
Intégration sous XCP-ng
Sous XCP-ng, Vates est allé plus loin dans l'intégration de LINSTOR/DRDB, puisque, via un partenariat avec LINBIT il propose XOSTOR.
Soit un packaging complet, conçu spécifiquement pour XCP-ng afin d'y déployer simplement et facilement LINSTOR/DRDB, sur un pool XCP-ng.
Plutôt que de réinventer la roue, Vates a choisi de s'appuyer sur une solution éprouvée et fiable pour fournir une intégration simplifiée et embarquée dans leur hyperviseur.
Si on résume :
- DRBD s'occupe de répliquer les données des VM entre les serveurs.
- LINSTOR gère la création et le placement des volumes.
- XOSTOR fournit l'intégration de DRDB/LINSTOR sous XCP-ng.
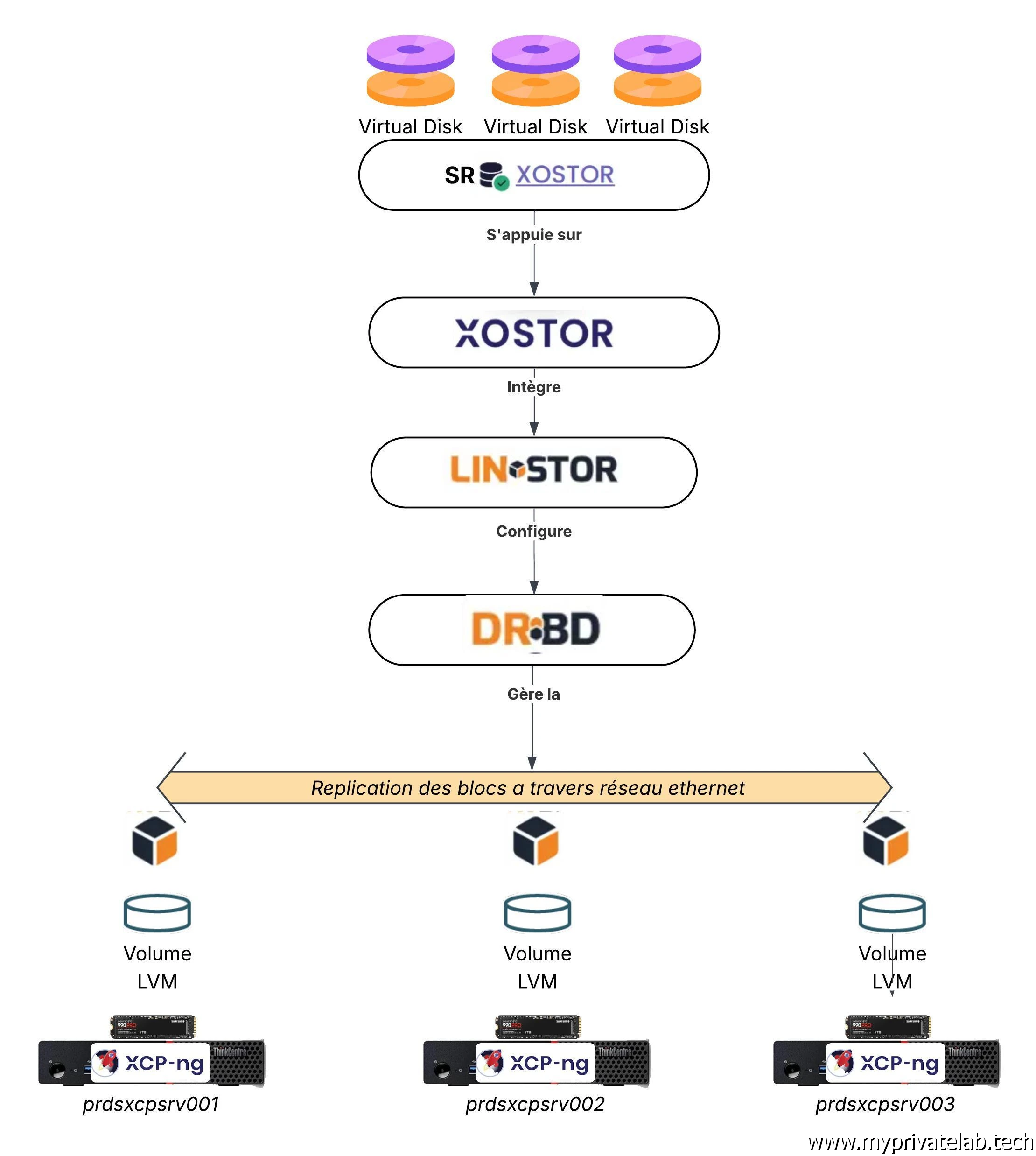
Cliquez sur l'image pour l'agrandir.
Notre problème est qu'en version gratuite, même à partir des sources, l'ajout de la GUI accompagnant XOSTOR n'est pas possible, du moins je n'ai pas trouvé comment.
Cliquez sur l'image pour l'agrandir.
Mais comme tout est open source, il reste la possibilité d'exploiter tout le système via une installation manuelle, certes plus fastidieuse, mais tout à fait compatible avec notre pool.
Si nous ne pouvons pas utiliser la simplicité de XOSTOR, nous pourrons au moins exploiter son driver pour construire un SR global au pool tirant parti du reste de l'espace libre de chacun des disques locaux des trois serveurs.
Pour rappel, à l'installation de XCP-ng, nous avons volontairement créé un SR local de taille limitée pour laisser le reste du disque à la création de volumes répliqués.
Déploiement
Relevé de la conf disque actuelle
Sur chaque serveur, il faut se connecter en SSH pour exécuter >fdisk sur le disque nvme et relever la configuration actuelle via l'option p.
Nous n'allons pas à ce stade créer de partition, mais il est important de savoir à partir de quel emplacement (en Go) nous devrons créer la prochaine partition primaire.
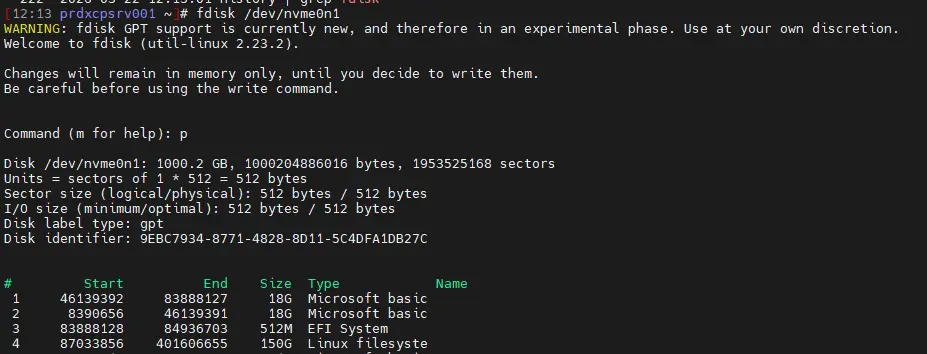
Cliquez sur l'image pour l'agrandir.
Dans le cas de mon lab avec la configuration matérielle décrite en introduction de ce cookbook, et après avoir créé le SR local de 150 Go sur chaque serveur, ma future partition démarrera à 206 Go.
Le point de départ de ma prochaine partition à 206 Go s'explique par l'emplacement du dernier secteur utilisé sur mon disque, le secteur 401 606 655. En multipliant ce numéro de secteur par sa taille de 512 octets, on obtient un total de 205 622 607 360 octets déjà occupés ou réservés, ce qui correspond précisément à 205,6 Go. J'arrondis à 206 Go
C'est un peu tiré par les cheuveux et il doit certainement y'avoir une méthode plus simple. On pourrait d'ailleur des à présent créér la partition suivante en partant simplement de ce que fdisk proposerait par défault, mais ce point est traité plus loin.
Préparation du Dom0
Avant de poursuivre, il reste une toute petite chose à faire qui va nous éviter des problèmes par la suite: augmenter la mémoire de la VM du Dom0.
Rappelez-vous que, dans les articles précédents, nous avons traité de la VM du Dom0, celle déployée lors de l'installation de XCP-ng, et qui permet d'échanger directement avec l'hyperviseur Xen pour la gestion et le suivi du serveur.
Par défaut cette VM vient avec une quantité réduite de RAM (2 Go), ce qui est suffisant lorsqu'on ne cherche pas à déployer d'autres composants, mais qui peut se montrer limité si on commence à lui ajouter des éléments supplémentaires… Comme tout un système de réplication de blocs.
En effet, DRBD/LINSTOR vont tourner dans le Dom0 et risquent de consommer davantage de ressources (y'a du Java…). Si la VM du Dom0 vient à saturer en RAM, alors on peut s'exposer à des instabilités du pool et des serveurs.
Cliquez sur l'image pour l'agrandir.
On peut vérifier le statut actuel de la VM via la commande xl list.
On voit que la VM du dom0 dispose de peu de RAM.

Cliquez sur l'image pour l'agrandir.
Pour procéder aux modifications, on peut appeler directement la commande :
/opt/xensource/libexec/xen-cmdline --set-xen dom0_mem=6144M,max:6144M
Cliquez sur l'image pour l'agrandir.
En réalisant cette instruction sur chacun des serveurs, on bascule la VM à 6 Go de mémoire. On pourrait se contenter de 4 Go mais j'ai préféré prendre un peu de mou… même si à l'heure d'écriture de cet article, 1 Go de RAM devient une ressource rare et chère…
Cependant, pour que le changement soit pris en compte, il faut redémarrer chaque node.
À ce stade, avant que le HA soit actif et sans réplication de blocs, on peut couper simplement notre VM Xen Orchestra (prdxcpxor501) et notre VM de test créée dans l'article précédent.
Cliquez sur l'image pour l'agrandir.
N'hésitez pas à interroger le statut des VMs avec la commande xe vm-list, pour bien vous assurer que chaque VM est eteinte avant de faire le reboot des serveurs XCP-ng.

Cliquez sur l'image pour l'agrandir.
Il faut bien attendre l'exctinction de toute les VMs (hors domain0), et comme XO n'est plus disponible, il va falloir opérer un reboot des serveurs via SSH avec la commande reboot now, en redémarrant le master à la fin.
Une fois que chaque serveur XCP-ng sera de nouveau opérationnel, XO devrait redémarrer automatiquement si l'auto-amorçage a été activé.
Sinon, pour rappel, XO n'est pas un prérequis au bon fonctionnement du pool.
On peut se connecter à l'un des serveurs XCP en ssh et relancer manuellement la VM via la commande xe vm-start (l'opération peut se faire depuis n'importe quel serveur, la commande sera relayée au master du pool).

Cliquez sur l'image pour l'agrandir.
Une fois que tout est à nouveau UP, on peut poursuivre l'installation de XORSTOR.
Installation des packages
On commence tout simplement par déployer les packages xcp-ng-release-linstor et xcp-ng-linstor sur chaque serveur :
yum install xcp-ng-release-linstor
yum install xcp-ng-linstor
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Initialisation et ouverture firewall
Comme nous l'avons expliqué plus haut, LINSTOR fonctionne en utilisant le principe de contrôleur et de satellite.
Pour plus de simplicité, nous allons considérer que pour initier notre configuration, le contrôleur sera porté par le master du pool. Attention, cela pourrait changer en permanence, car le contrôleur pourrait être redirigé vers un autre serveur en cas d'incident. C'est d'ailleurs la raison pour laquelle on est obligé d'avoir au moins trois serveurs pour déployer XOSTOR. Comme pour le HA du pool XCP-ng, il faut un minimum de nodes pour assurer l'élection du master (ou du contrôleur pour XOSTOR).
Donc, on se connecte en SSH sur le master du pool.
On s'assure que les services fraîchement installés sont actifs :
systemctl enable --now linstor-controller
systemctl enable --now linstor-satelliteOn ouvre les flux firewall qui vont être nécessaires à DRBD/LINSTOR, soit les ports 3366, 3370 et les ports 7000 à 7999 :
iptables -I INPUT -p tcp --dport 3366 -j ACCEPT
iptables -I INPUT -p tcp --dport 3370 -j ACCEPT
iptables -I INPUT -p tcp --dport 7000:7999 -j ACCEPTOn sauvegarde la conf iptables :
service iptables saveOn restart le service satellite :
systemctl restart linstor-satelliteOn laisse sa connexion SSH active sur le serveur master et on passe sur les autres hosts pour rejouer à peu près la même chose (sans démarrer le controller) pour avoir également les ports ouverts :
systemctl enable --now linstor-satellite
iptables -I INPUT -p tcp --dport 3366 -j ACCEPT
iptables -I INPUT -p tcp --dport 3370 -j ACCEPT
iptables -I INPUT -p tcp --dport 7000:7999 -j ACCEPT
service iptables save
systemctl restart linstor-satellite
Cliquez sur l'image pour l'agrandir.
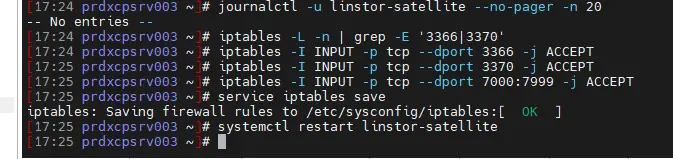
Cliquez sur l'image pour l'agrandir.
On retourne sur le master et on va dans un premier temps utiliser linstor pour créer notre pool de stockage en intégrant les machines qui vont y participer et en déclarant le master du pool XCP comme contrôleur :
linstor node create prdxcpsrv001 192.168.12.1 --node-type Combined
linstor node create prdxcpsrv002 192.168.12.2 --node-type Satellite
linstor node create prdxcpsrv003 192.168.12.3 --node-type Satellite
Cliquez sur l'image pour l'agrandir.
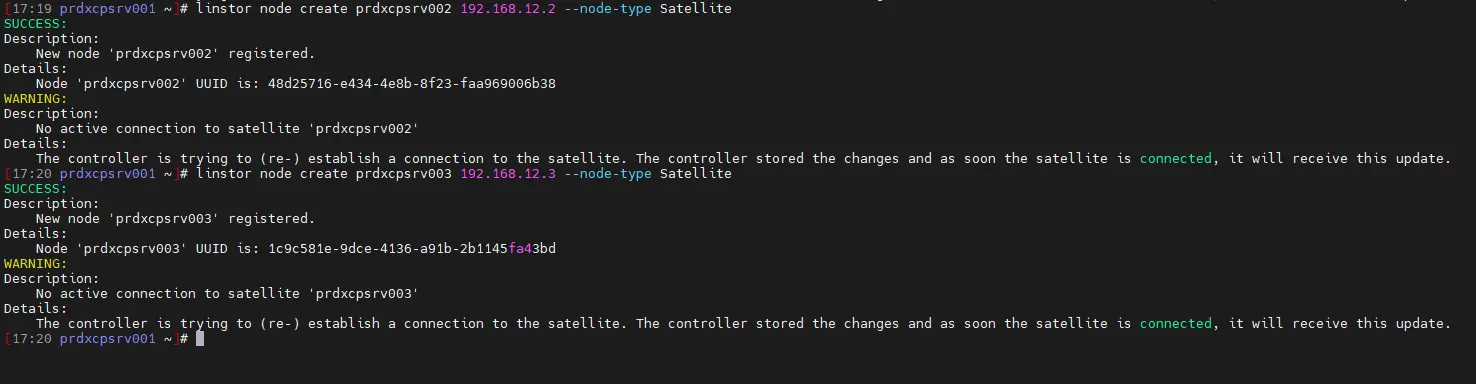
Cliquez sur l'image pour l'agrandir.
Notez qu'on utilise bien les IPs locales attribuées à notre VLAN de storage créé dans l'article précédent. C'est très important, sinon toute la réplication pourrait passer par la carte 1G des serveurs, et les performances seraient catastrophiques.
On peut vérifier la conf avec la commande :
linstor node list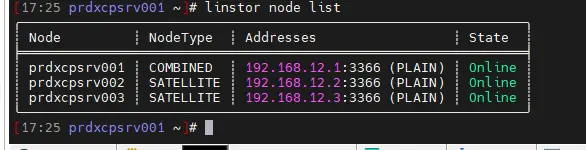
Cliquez sur l'image pour l'agrandir.
Création des volumes
Il va falloir maintenant créer notre partition sur chaque node qu'on va dédier à DRBD.
Node par node on réalise les commandes suivantes :
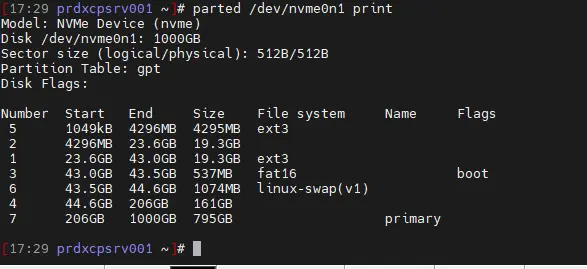
parted /dev/nvme0n1 mkpart primary 206GB 1000GB
parted /dev/nvme0n1 print
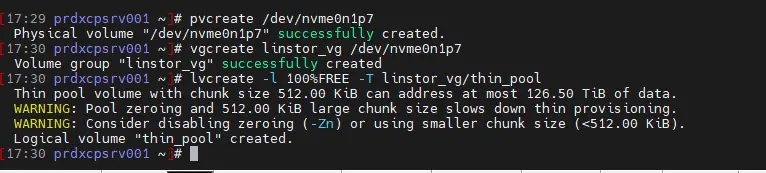
pvcreate /dev/nvme0n1p7
vgcreate linstor_vg /dev/nvme0n1p7
lvcreate -l 100%FREE -T linstor_vg/thin_pool
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
La volumétrie retenue et les parametres de partition sont propres à mon lab et ma configuration matérielle (a adapter fonction de vos configurations). On reprent les 206 Go identifiés en début d'article. Ne vous inquiétez pas l'alignement des partitions est automatiquement pris en compte par la commande parted.
Globalement il s'agit de créer sur chaque serveur, une partition LVM en exploitant tout l'espace disque restant sur le disque nvme.
Le nom complet du volume logique sur chaque node est linstor_vg/thin_pool.
C'est cette définition qu'on va utiliser en revenant sur le premier serveur (le contrôleur) pour associer ces volumes à notre pool DRDB configuré avec Linstor.
On va donc créer ce pool de storage xostor_pool en combinant les volumes logiques locaux linstor_vg/thin_pool de chaque serveur :
linstor storage-pool create lvmthin prdxcpsrv001 xostor_pool linstor_vg/thin_pool
linstor storage-pool create lvmthin prdxcpsrv002 xostor_pool linstor_vg/thin_pool
linstor storage-pool create lvmthin prdxcpsrv003 xostor_pool linstor_vg/thin_pool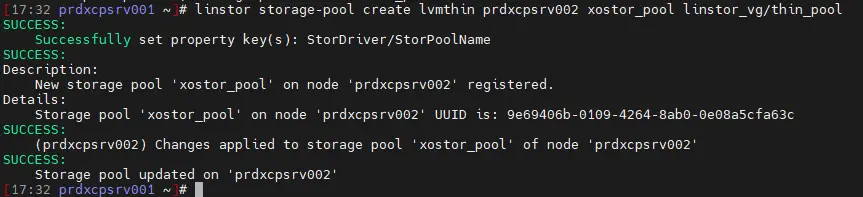
Cliquez sur l'image pour l'agrandir.
On peut vérifier la configuration avec la commande linstor storage-pool list

Cliquez sur l'image pour l'agrandir.
Afin que cette nouvelle source de stockage soit visible de XCP-ng, il faut redémarrer sur chaque serveur le service xe-toolstack (le service console de xcp-ng) :
xe-toolstack-restart
Cliquez sur l'image pour l'agrandir.
Création du SR
On retourne sur le master (le contrôleur), car on va maintenant créer le SR basé sur la configuration XORSTOR.
Pour ça on utilise les commandes suivantes :
# Récupérer l'UUID du pool master
xe host-list params=uuid,hostname
xe sr-create type=linstor name-label="XOSTOR" \
host-uuid=3e0daa17-41a7-45a8-b2fb-bef287aa11e6 \
device-config:group-name=linstor_vg/thin_pool \
device-config:redundancy=2 \
device-config:provisioning=thinSi on décortique ce qu'on a fait, on a créé un SR XOSTOR sur le master (en ayant récupéré son UUID avant).
Ce SR est de type linstor et dispose d'une redondance de 2. Cela implique que, pour chaque VM déployée sur ce SR, sa data sera à minima répliquée 2× sur deux serveurs différents.
Ceci nous permet de supporter la perte d'un node sur les trois. En effet, avec cette configuration, une VM pourra toujours être redémarrée sur un nœud survivant et retrouver sa donnée soit nativement sur le nouveau serveur retenu pour démarrer la VM, soit à travers le réseau de stockage sur l'autre node restant.
Immédiatement, la réplication va reprendre pour revenir à deux.
Toutefois, cela signifie que, contrairement à l'hébergement d'une VM sur un SR local uniquement, une VM sur le SR XOSTOR consommera deux fois plus de données sur la capacité totale du pool.
Assurance supplémentaire pour les interfaces réseau
Lors du déploiement, j'ai rencontré une erreur où, sans que je puisse l'expliquer, la réplication avait basculé sur les IPs associées aux cartes 1G des serveurs. (Je m'en suis aperçu lors des tests de performance.)
J'ai donc dû forcer le passage aux IPs associées au VLAN de storage, comme déclaré plus haut, dans la conf linstor-client de chaque serveur.
Pour tous les serveurs du pool, il est préférable de forcer cette configuration :
cat > /etc/linstor/linstor-client.conf << EOF
[global]
controllers=linstor://192.168.12.1,linstor://192.168.12.2,linstor://192.168.12.3
EOF
Cliquez sur l'image pour l'agrandir.
Et retaper depuis le master les commandes suivantes :
linstor node interface modify prdxcpsrv001 default --ip 192.168.12.1
linstor node interface modify prdxcpsrv002 default --ip 192.168.12.2
linstor node interface modify prdxcpsrv003 default --ip 192.168.12.3
linstor node list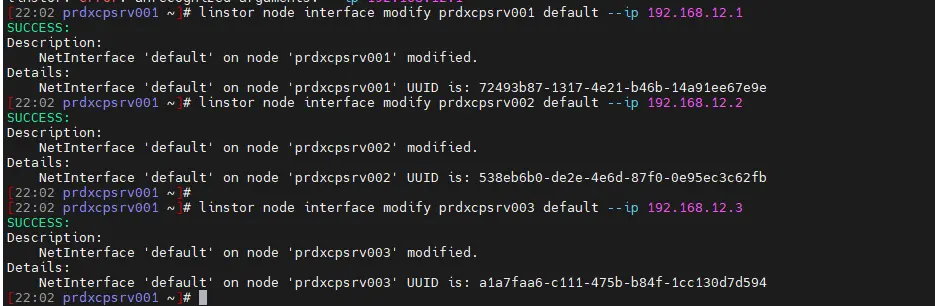
Cliquez sur l'image pour l'agrandir.
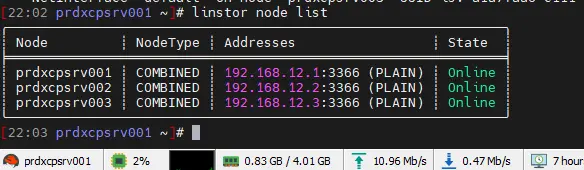
Cliquez sur l'image pour l'agrandir.
Configuration du SR et mappage aux autres nodes
Pour indiquer que le SR est partagé au niveau du pool, il faut encore passer par la récupération du label du SR XOSTOR pour lui attribuer le paramètre shared à true:
xe sr-list name-label="XOSTOR"
xe sr-param-set uuid=6a7bbd54-6eed-8eb0-ce75-3aa975764eb7 shared=true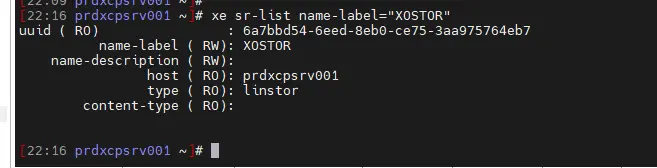
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
Il faut également associer cette UUID aux autres serveurs.
Sur prdxcpsrv002 :
xe pbd-create sr-uuid=6a7bbd54-6eed-8eb0-ce75-3aa975764eb7 \
host-uuid=$(xe host-list name-label=prdxcpsrv002 --minimal) \
device-config:group-name=linstor_vg/thin_pool \
device-config:redundancy=2 \
device-config:provisioning=thin
xe pbd-plug uuid=f410da6e-8346-9414-4541-8a8ffe0cb3e4
Cliquez sur l'image pour l'agrandir.
Sur prdxcpsrv003 :
xe pbd-create sr-uuid=6a7bbd54-6eed-8eb0-ce75-3aa975764eb7 \
host-uuid=$(xe host-list name-label=prdxcpsrv003 --minimal) \
device-config:group-name=linstor_vg/thin_pool \
device-config:redundancy=2 \
device-config:provisioning=thin
xe pbd-plug uuid=3dcc1915-9247-10d7-b7aa-33d353c2b024
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
Sur ces dernières commandes, le but est de créer un PBD soit un Physical Block Device. C'est un connecteur qui lie un hôte à un SR.
En effet, si on a initié le SR sur prdxcpsrv001, il faut le connecter aux autres serveurs, d'où la commande xe pbd-plug uuid à ne pas oublier qui pointe vers l'UUID du PBD qu'on vient de créer (et non vers l'UUID du SR).
Pour être sûr que tout soit pris en compte du côté XCP-ng, il vaut mieux sur chaque node refaire un redémarrage de la stack de management :
xe-toolstack-restartOn peut maintenant vérifier le statut gobal de la configuration finale avec les commandesa:
linstor resource listlinstor node listlinstor storage-pool listDéplacement de VMs
Affichage dans Xen Orchestra
Si on se connecte à la GUI de Xen Orchestra, notre nouveau SR apparaît bien :
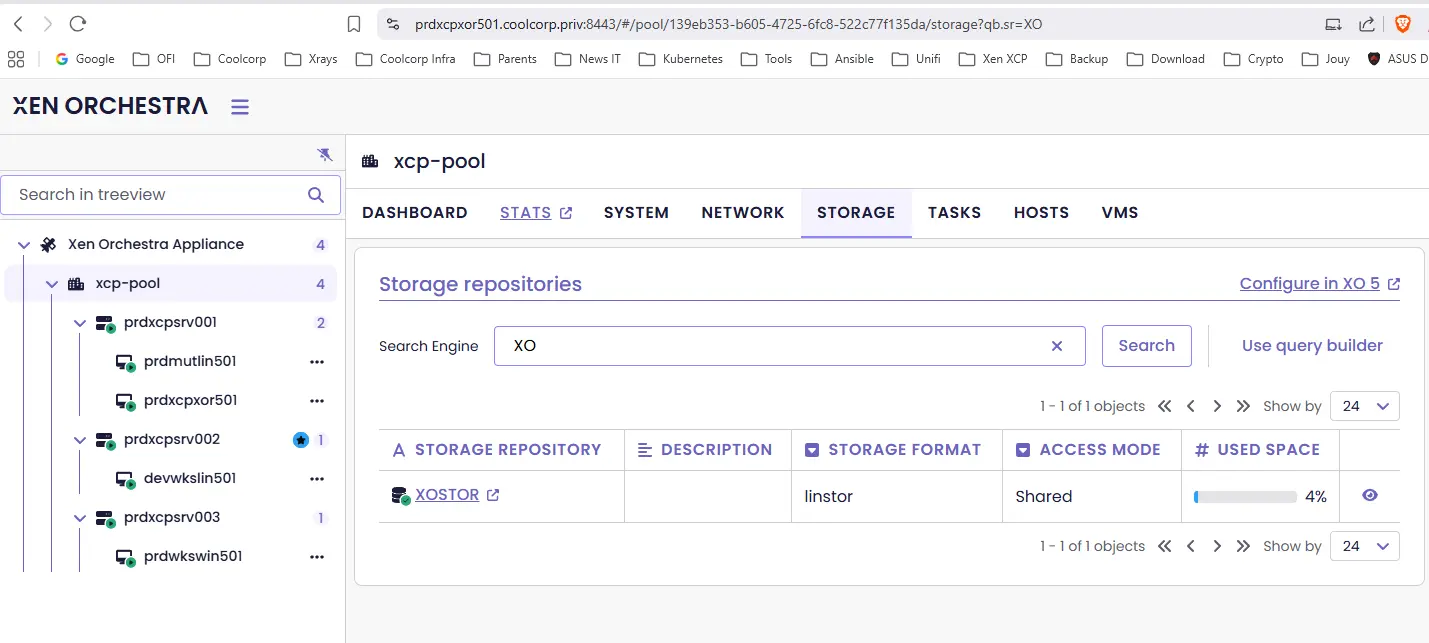
Cliquez sur l'image pour l'agrandir.
En examinant de près, on constate la somme de l'espace de chaque volume logique global de chaque serveur, en soustrayant la redondance requise, ce qui équivaut à environ 1 To.
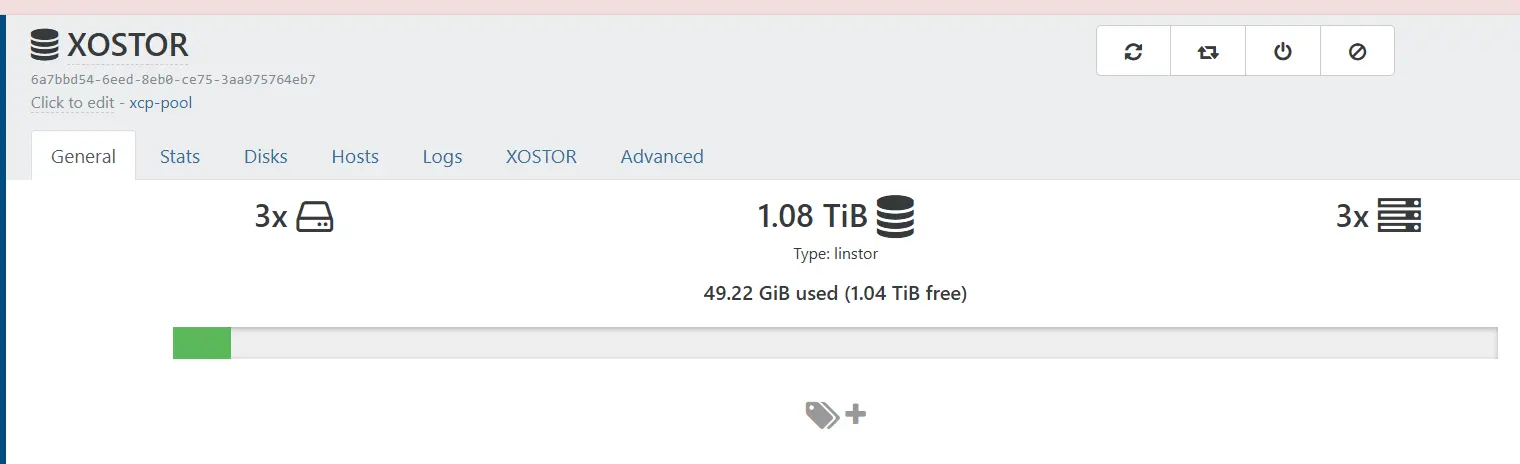
Cliquez sur l'image pour l'agrandir.
On note aussi la connexion aux trois serveurs du pool. Il est temps maintenant de passer au test.
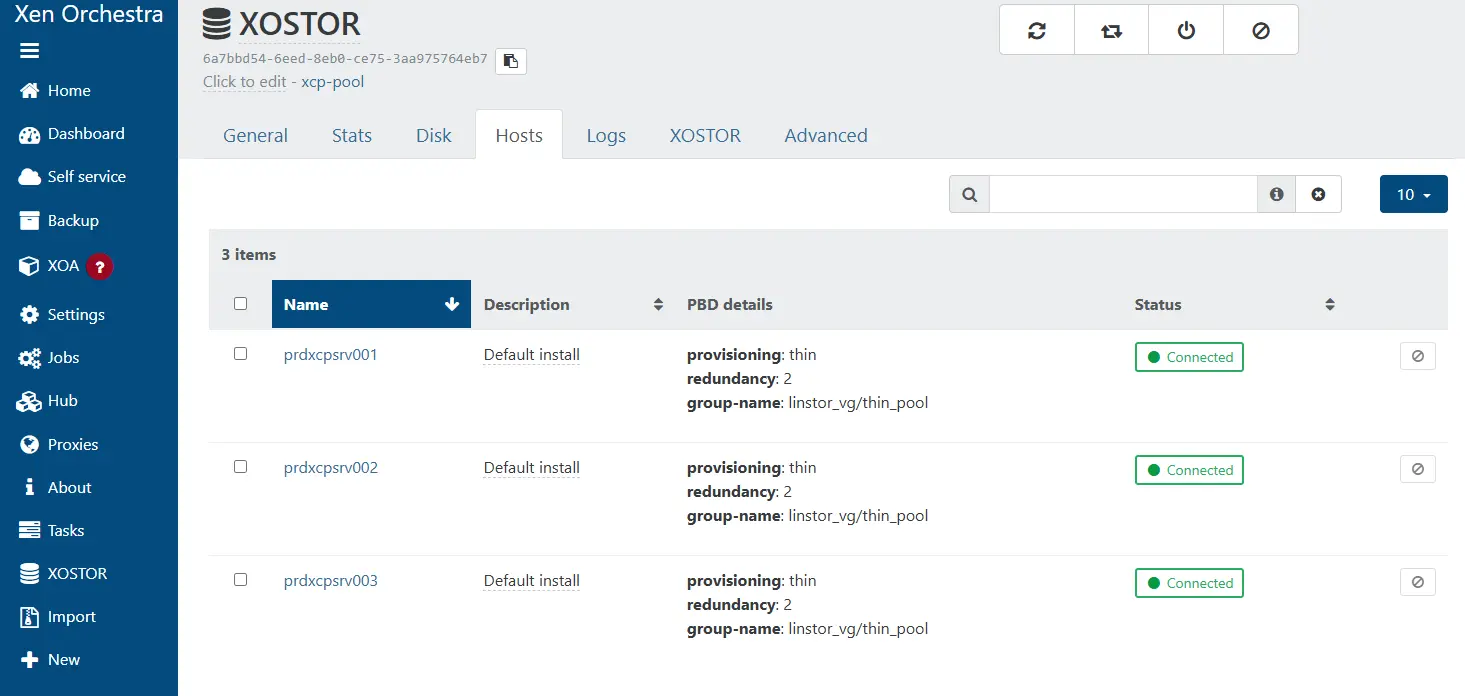
Cliquez sur l'image pour l'agrandir.
Déplacement de SR via "Migrate VDI"
Pour ça, on va repartir de la VM de test sous Zorin OS (mon nouvel OS client préféré), qu'on avait déjà utilisée lors de l'article précédent pour tester la migration d'une VM de serveur à serveur. On avait alors observé une coupure et un redémarrage de la VM.
Voyons ce que ça donne à présent. On l'avait laissée sur prdxcpsrv002. Actuellement ses données sont sur le SR local à prdxcpsrv002 :
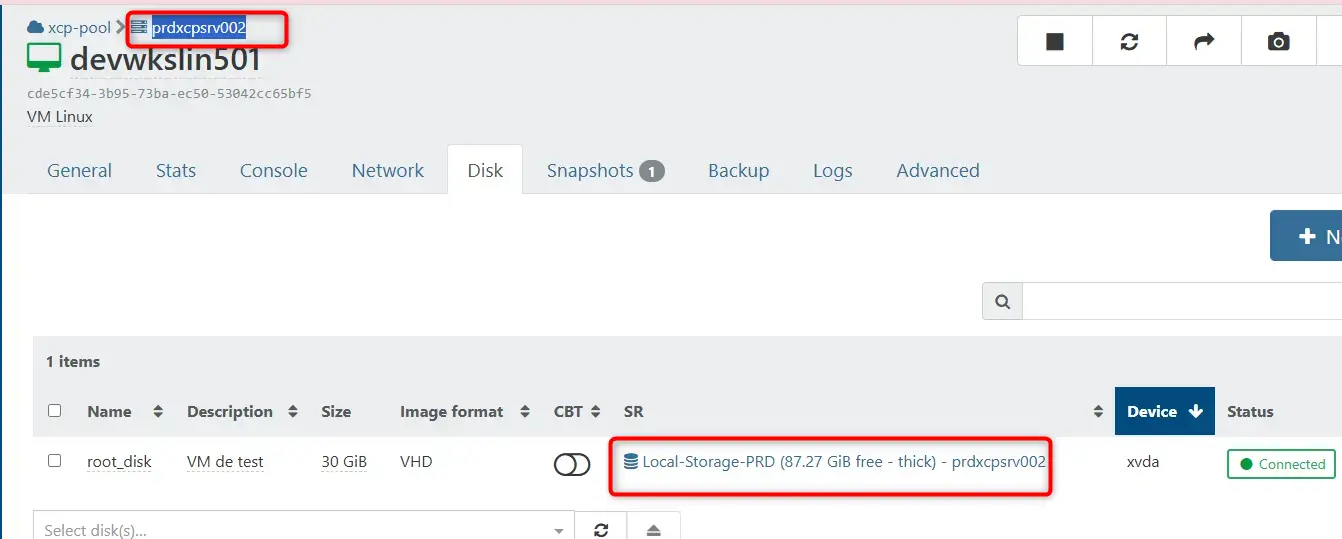
Cliquez sur l'image pour l'agrandir.
Essayons déjà de la déplacer sur notre nouveau SR. Comme la dernière fois, on va laisser tourner des pings entre mon poste de travail et la VM.
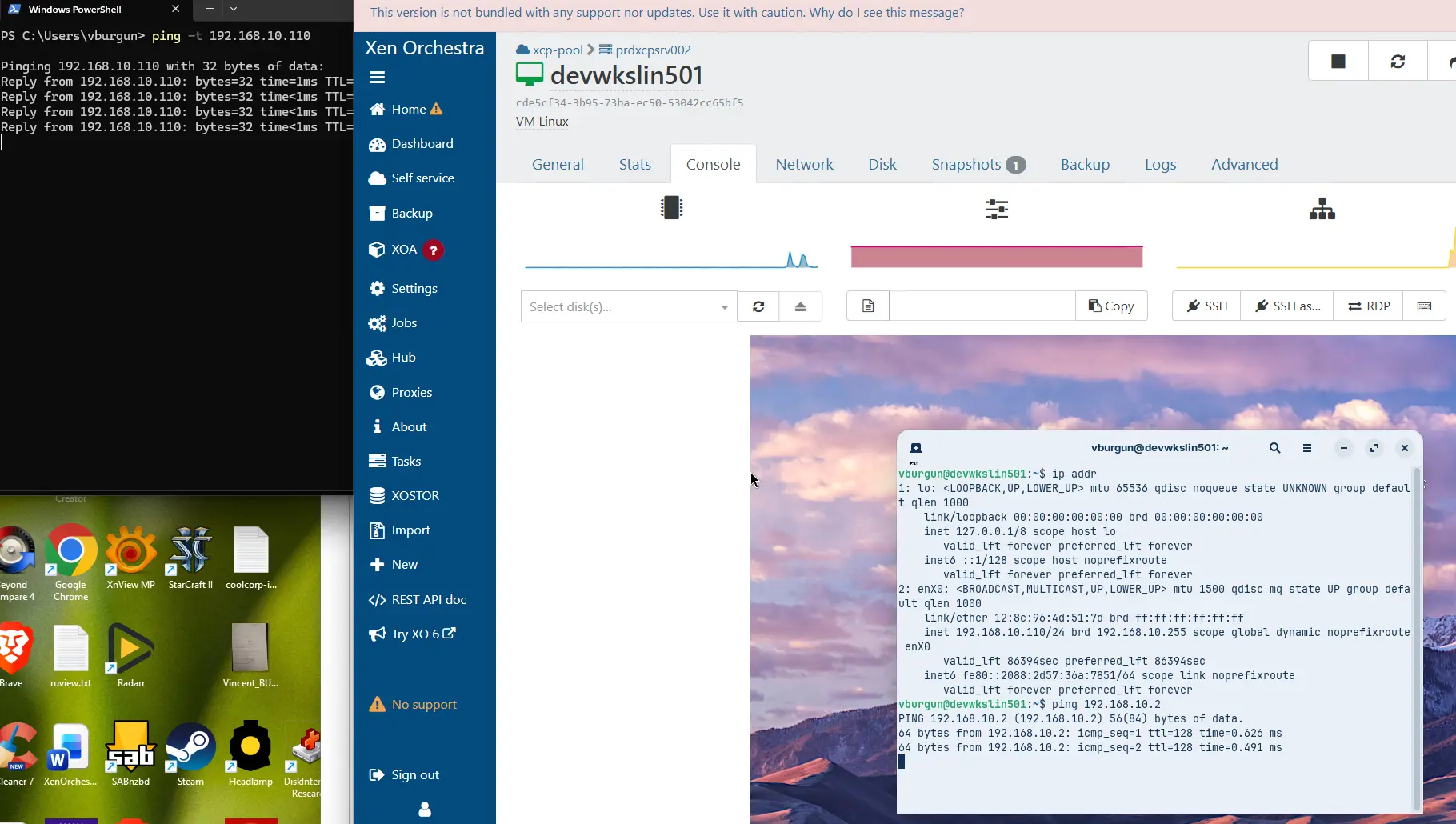
Cliquez sur l'image pour l'agrandir.
En revanche, on ne va pas utiliser l’option Warm Migration, car prdxcpsrv002 dispose d’un accès au deux SR. Le SR source qui n’est présent que sur prdxcpsrv002 et le SR XOSTOR de destination partagé sur l’ensemble du pool.
On peut donc faire l’équivalent d’un storage vMotion en déplaçant uniquement le stockage de la VM tout en conservant le contexte d’exécution sur le serveur.
Pour cela, on agit directement dans l’onglet Disk de la VM et on sélectionne l’option de déplacement Migrate VDI.
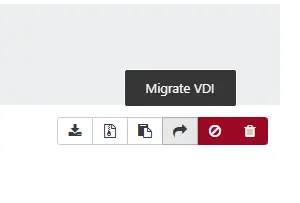
Cliquez sur l'image pour l'agrandir.
On sélectionne le nouveau SR XOSTOR, et immédiatement, on peut suivre le déroulé des actions depuis la section Tasks de Xen Orchestra.
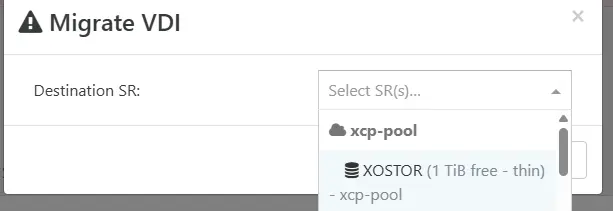
Cliquez sur l'image pour l'agrandir.
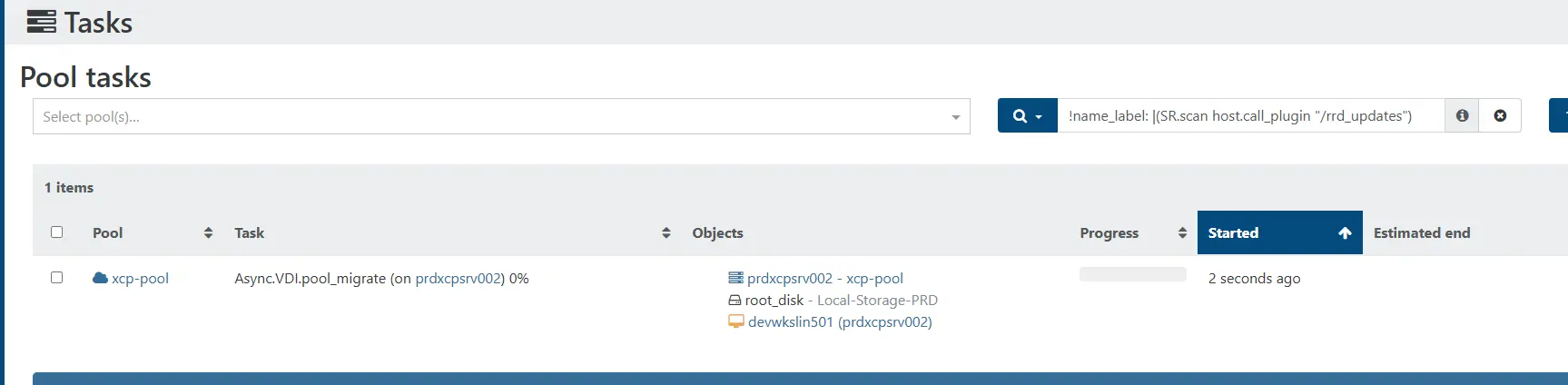
Cliquez sur l'image pour l'agrandir.
(Merci à Camille Lacuve de m’avoir signalé cette capacité de migration que je ne connaissais pas, ce qui m’a permis de mettre à jour mon article).
Contrairement à la fois précédente, on n’observe que la perte de deux ping durant le déplacement des données et la VM ne redémarre pas.
Cliquez sur l'image pour l'agrandir.
La VM est toujours sur prdxcpsrv002 mais maintenant sur le SR XOSTOR :
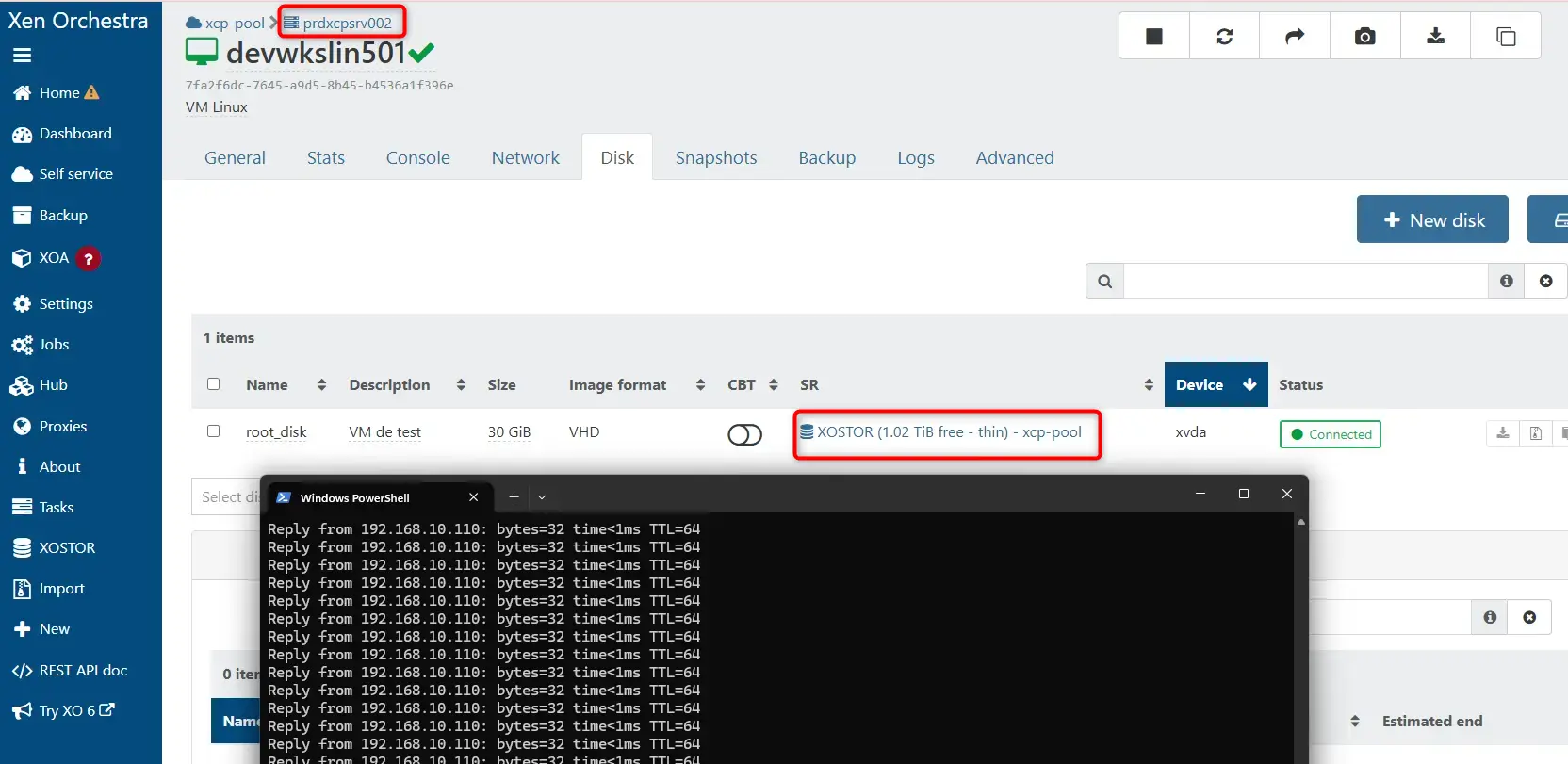
Cliquez sur l'image pour l'agrandir.
Déplacement de serveur via Live Migration
Essayons une autre technique de migration, soit l'option Live Migration, qui se trouve cette fois-ci sur l'onglet principal de la VM. Le but va etre de déplacer la VM d'un serveur à un autre.
Cliquez sur l'image pour l'agrandir.
Déplaçons cette dernière sur prdxcpsrv001, en conservant le disque sur le SR XOSTOR et en sélectionnant le réseau VLAN storage pour le déplacement :
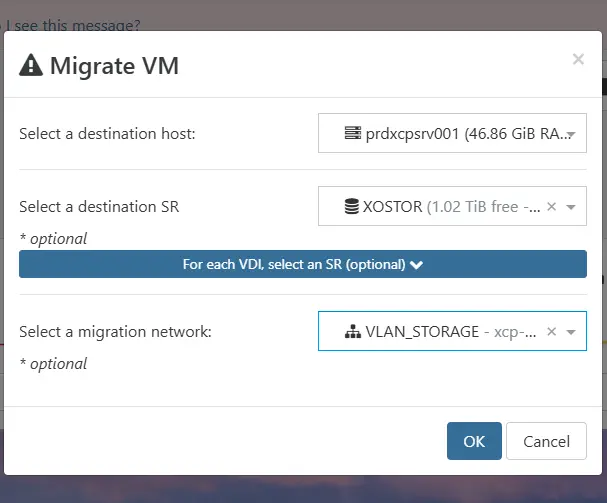
Cliquez sur l'image pour l'agrandir.
La tâche s'effectue immédiatement, mais elle ne dure que quelques secondes et ne fait perdre qu'un seul ping :
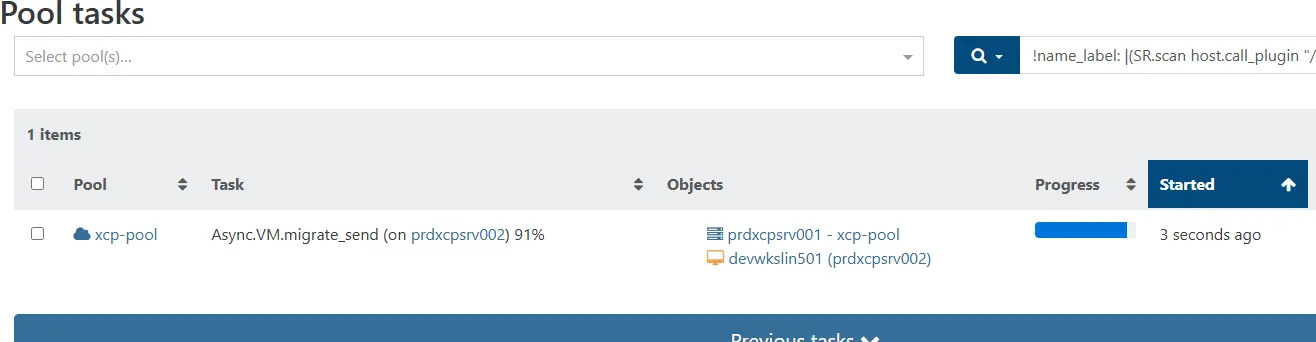
Cliquez sur l'image pour l'agrandir.
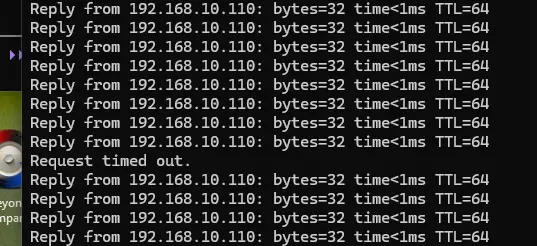
Cliquez sur l'image pour l'agrandir.
La VM est restée allumée et dans son contexte, tout en étant migrée sur le premier serveur :
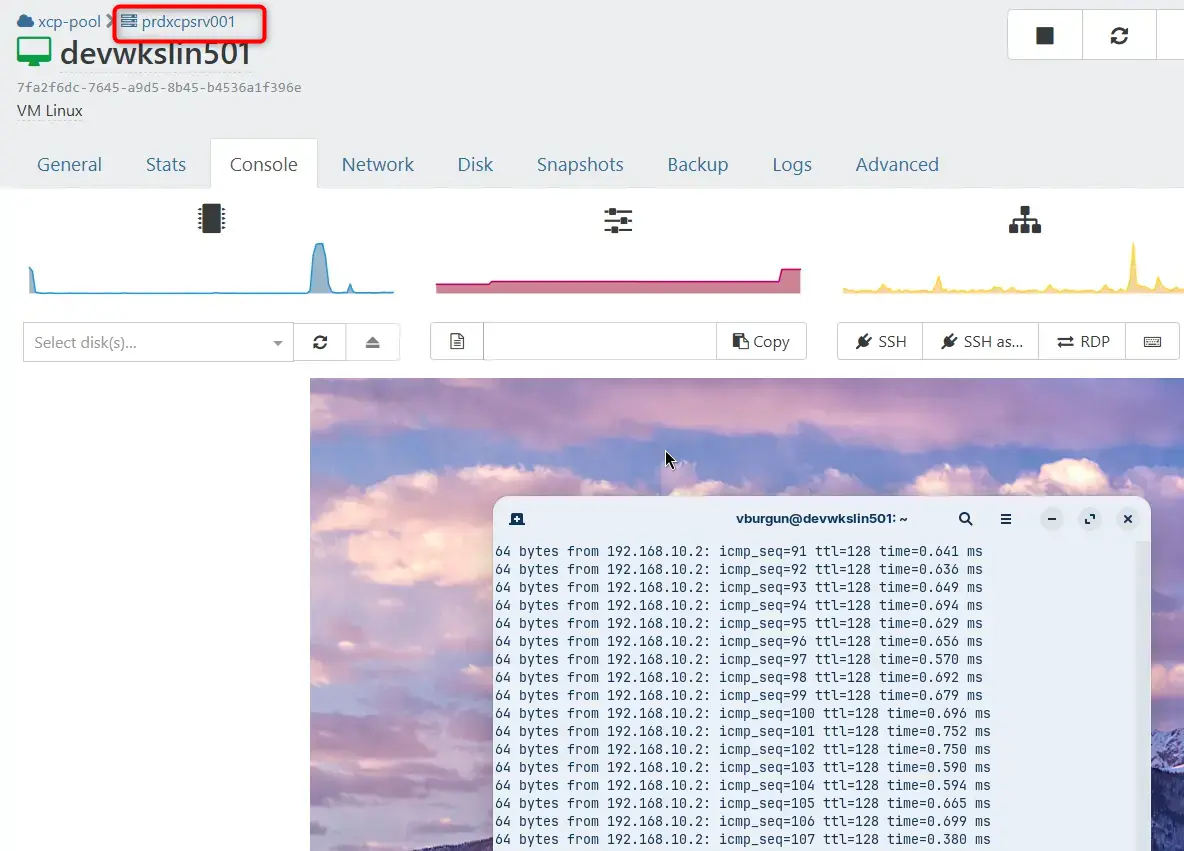
Cliquez sur l'image pour l'agrandir.
C'est tout aussi efficace qu'un vMotion chez VMware et le contexte mémoire a bien été déplacé, à chaud, d'un serveur à un autre.
C'est la différence avec notre Warm Migration précédent. Lorsque la Warm Migration prend un snapshot de la VM source pour le copier à la destination et redémarrer la VM à partir de ce dernier, la Live Migration déplace simplement le contexte mémoire. Ceci est rendu possible par la présence du SR XOSTOR partagé entre tous les serveurs du pool.
Les deux présentent un intérêt et répondent à des besoins différents, mais, maintenant qu'on a un pool et un stockage partagés, il n'y a plus de raison de faire une migration Warm. Voici un petit récapitulatif des deux méthodes:
| Caractéristique | Live Migration (XenMotion) | Warm Migration |
|---|---|---|
| État de la VM | Allumée (Running) | Allumée pendant le transfert, puis éteinte brièvement |
| Coupure de service | Quelques millisecondes à une seconde | Plusieurs minutes |
| Usage principal | Déplacement entre hôtes du même pool | Migration entre deux SR différents ou deux pools distincts |
| Vitesse | Très rapide (transfert de RAM uniquement) | Plus lente (transfert des disques complets) |
Il est à noter qu’il est désormais possible de déplacer une VM hébergée sur le SR XOSTOR vers un SR local d’un serveur différent (qui ne l'exécute pas actuellement) sans interrompre les services, en suivant simplement ces deux étapes:
- On fait un Live Migration vers le serveur qui dispose du SR local.
- Une fois le contexte mémoire déplacé sur le serveur cible, on effectue un Migrate VDI vers le SR local du serveur, comme vu dans la partie précédente (mais dans l’autre sens).
Évaluation des performances
Reste un dernier point à évaluer : les performances.
En effet, j'ai démarré mon article en indiquant que je ne pouvais pas utiliser NFS comme protocole pour créer un SR partagé dédié aux VMs à cause des performances. Voyons si le choix de se tourner vers XOSTOR est plus pertinent.
Pour cela, on va exploiter un simple benchmark des performances du disque depuis la VM. Habituellement sous W11, pour un test rapide et synthétique, j'utilise CrystalDiskMark. Mais il n'est pas disponible sous Linux. Heureusement, un clone appelé KdiskMark fait la même chose, et il est directement disponible dans la boutique d'applications de Zorin OS.
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
On va donc l'installer et l'exécuter. Voici le résultat :
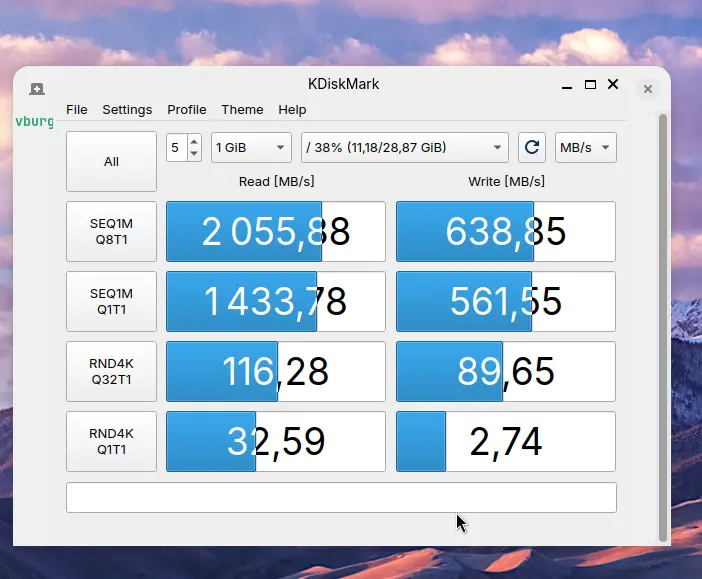
Cliquez sur l'image pour l'agrandir.
En lecture, on voit qu'on est parfaitement dans les performances d'un SSD NVMe. En revanche, en écriture le maximum atteignable est 638,85 MB/s soit 5,1 Gbps.
Déjà ça confirme qu'on n'exploite pas un réseau giga, puisqu'on est plus de 5× au-dessus du débit max offert par un lien classique. C'est bien le 10 Gbit/s qui est utilisé pour la réplication des données.
D'ailleur à titre d'informations, lorsque je vous parlais plus haut que j'avais rencontré une erreur de basculement de la réplication sur les interfaces 1G, voici les résultats que j'avais obtenus à ce moment-là sur une VM de test Windows.
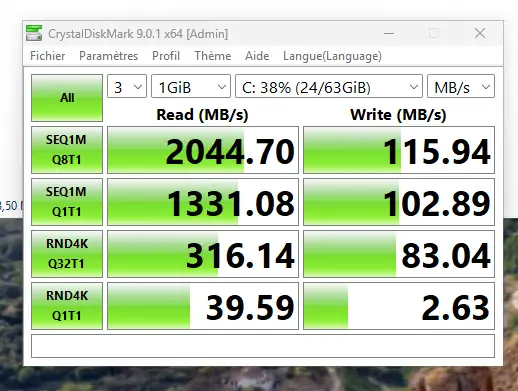
Cliquez sur l'image pour l'agrandir.
Toutefois malgrès l'usage du lien 10G, on est à environ 50 % de la bande passante théorique d'un tel débit, sans parler des performances en écriture aléatoire 4K…, mais c'est finalement normal puisque nous avons exigé une réplication de deux pour toutes les VM hébergées sur le SR XOSTOR.
Cela implique que, pour chaque opération d'écriture, il faut attendre l'acquittement de deux serveurs du pool pour réellement considérer la donnée comme inscrite, et, pour ça, même 10G entraîne forcément une latence et une réduction des perfs.
Il ne faut pas oublier également que mon lab tourne sur des serveurs qui sont en fait des machines bureautiques recyclées avec des CPU d'entrée de gamme et des performances réduites. Côté réseau, comme on l'avait déjà fait remarquer lors de sa mise en œuvre, les 10G sont bien là. J'ai même réalisé des tests avec iperf entre deux serveurs du pool, on dispose du maximum possible qu'on puisse obtenir. Le réseau est donc parfaitement configuré.
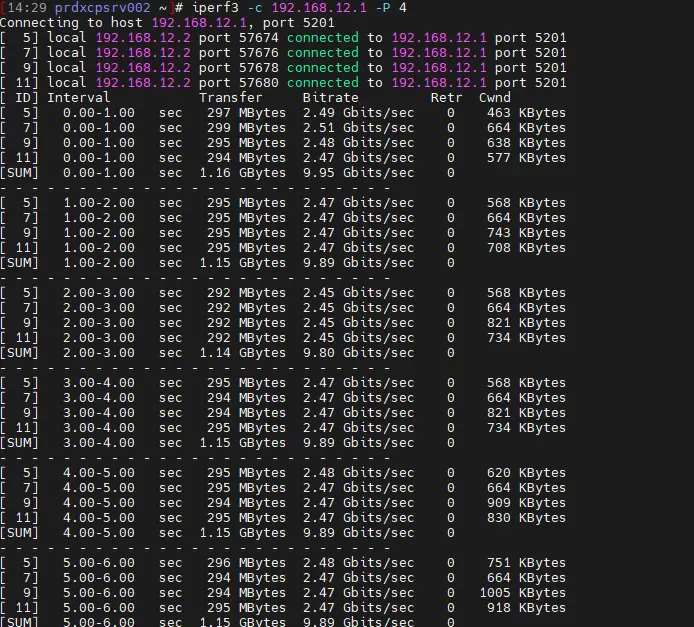
Cliquez sur l'image pour l'agrandir.
À noter que comme cité précédemment, j'ai également fait des essais avec une VM Windows, et j'ai des résultats dans le même ordre de grandeur, voire meilleurs en écriture.
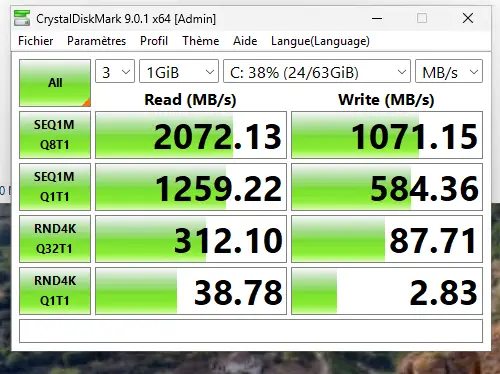
Cliquez sur l'image pour l'agrandir.
À ce niveau aussi, il peut y avoir des différences, entre la quantité de RAM de la VM, le driver disque, le driver des outils Xen installés dans l'OS virtuel et l'outil de benchmark en lui-même.
En définitive, le besoin de répliquer la donnée, combiné à l'utilisation d'un matériel serveur minimaliste et aux aléas de la configuration OS, cela implique inévitablement des limites dans les performances. Mais c'est largement admissible pour un homelab et pour des usages courants. Même une base de données, plutôt liée à de l'écriture séquentielle, peut fonctionner sur cette configuration.
Conclusion
On a maintenant tout ce qu'il faut pour avoir une plateforme de virtualisation XCP-ng résiliente et performante (en rapport à son usage). Même si en version gratuite, on ne bénéficie pas de la simplicité d'implémentation de XORSTOR, il est tout de même possible de l'installer. Celui-ci s'appuyant sur DRBD et LINSTOR, il s'avère parfaitement apte à couvrir le besoin d'exécution de VMs.
Il ne restera maintenant plus qu'à pousser la solution dans ses derniers retranchements et à tenter différents scénarios d'incidents pour évaluer la pertinence de XCP-ng pour couvrir des problématiques de HA. C'est l'objectif du prochain article qui conclura ce workbook dédié à l'écosystème de Vates.